

Heute erkläre ich den üblichen Prozess der Datenanalyse im Unternehmen (CRISP-DM) – und zwar anhand eines konkreten Projekts, welches ich im Rahmen des Udacity Data Science Nanodegrees abgeschlossen habe.
Dieser Standardprozess der Datenanalyse bzw. des Data Minings ist unter einem etwas komplizierten Namen als CRISP-DM Prozess bekannt. Ausgeschrieben und auf Englisch heißt es: Cross-industry standard process for data mining.
Vom Prinzip wird der Prozess allen denjenigen, die mit der wissenschaftlichen Methode der Forschung vertraut sind, bekannt vorkommen. Es ist sozusagen das, was manche in der Forschung als Research Design bezeichnen – nur nicht so anspruchsvoll.
Hier erkläre ich diesen Prozess anhand einer Analyse der AirBnB Unterkünfte in Berlin. Das Projekt ist auf meinem Github Account zu finden (Link).
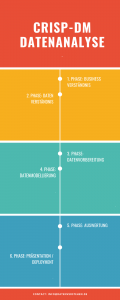
CRISP-DM – Phasen
Der CRISP-DM Prozess besteht aus sechs Phasen: 1. Business Understanding / Business Verständniss; 2. Data Understanding / Datenverständnis; 3. Data Preparation / Datenvorbereitung; 4. Modeling / Modellentwicklung; 5. Evaluation / Auswertung; 6. Deployment / Einsatz / Vorstellung.
1. Phase: Business Understanding – Fragen zum Geschäftsverständins
In dieser Phase werden die Fragen gestellt, die man für das eigene Business mit einer Datananalyse beantworten möchte. Was für Probleme und Fragen kommen im Unternehmen auf? Kann man diese Fragen anhand von Daten beantworten?
Zum Beispiel kann es gehen um die Frage:
- Wie akquiriere ich neue Kunden?
- Kann ich meine Kommunikation verbessern?
In meinem Projekt ging es dann u.a. um folgende Problemstellungen:
- In welchen Stadtteilen ist das Angebot an AirBnB Übernachtungen am größten?
- Welche Stadtteile sind die teuersten auf AirBnB?
- Welche Faktoren beeinflussen die Preisgestaltung?
2. Phase: Data Understanding – Verständnis der Daten
Hier geht es um das Verständnis der Daten, die zur Beantwortung der Fragen dienen sollen. Diese Phase kann auch in vielen Fällen der ersten Phase voraus gehen, denn oft hängen unsere Fragestellungen von der Verfügbarkeit der Daten ab. Aus diesem Grund kann der CRISP-DM Prozess mit den Daten anstelle der Fragestellungen anfangen: Was für Daten stehen uns zur Verfügung und welche Fragen können wir mit ihnen beantworten?
Wenn die Daten noch nicht vorhanden sind, müssen die Fragen sich zunächst um die Beschaffung der Daten drehen: Welche Daten werden bei der Beantwortung meiner Fragen helfen? Wo finde ich diese Daten?
In meinem konkreten Fall habe ich die erforderlichen Daten auf der offiziellen Webseite von AirBnB gefunden. Im zweiten Schritt habe ich die Fragen an die verfügbaren Daten angepasst und überprüft, was ich konkret mit diesen Daten beantworten kann.
Dieser Schritt der CRISP-DM ist auf meinem Github Konto unter folgendem Link zu finden.
3. Phase: Datenvorbereitung
Diese Phase ist die langwierigste Phase im gesamten Prozess der Datenanalyse. Experten schätzen, dass man alleine für diese Phase etwa 80% der gesamten Analysezeit verwendet.
Auch diese Phase geht Hand in Hand mit Phase eins und zwei. Insbesondere im Fall von Massendaten, die viele Variablen beinhalten, ist es ratsam den Datensatz erst einmal zu bereinigen, um zu überprfüen welche Fragestellungen anhand der Daten überhaupt beantwortet werden können.
Im konkreten Fall der AirBnB Daten habe ich im Anschluss die Daten bereinigt und nur die Variablen behalten, die für die weitere Analyse erforderlich waren. Hier nochmal der Link zu meinem Jupyter Notebook auf Github mit der Datenanalyse.
4. Phase: Datenmodellierung
Hier denken oft viele an die Anwendung komplexer Machine Learning Modelle. Die Realität ist aber, dass oft einfache Datenvisualisierungen und deskriptive Statistik ausreichen, um die wichtigsten Erkenntnisse aus den Daten zu ziehen.
Die Anwendung komplexer Modelle ist in diesem Fall optional.
Vom Prinzip beinhaltet ein Datenanalyseprozess folgende Zutaten: die Neugier richtige Fragen zu stellen, die relevanten Daten, Hilfsmittel (z.B. Excel, Tableau, Python) und eine gut erklärte Antwort auf die gestellte Frage.
Im Fall der AirBnB Analyse habe ich die letzten drei Phasen des CRISP-DM Prozess in einem Blogbeitrag auf Medium erfasst (Link). Basierend auf diesem Beispiel sieht man, dass einfache Visualisierungen in Python vollkommen ausreichend sind, um die gestellten Fragen zu beantworten.
Weitere Modellierung ist nur dann notwendig, wenn wir an konkreten Zusammenhängen interessiert sind.
Im AirBnB Fall wäre es zum Beispiel die Frage: was beeinflusst letztendlich die Preise der Unterkünfte in Berlin am meisten? Diese Frage wird in meinem Beispiel mit einer Regressionsanalyse beantwortet.
5. Phase: Auswertung
In der fünften Phase geht es um die Auswertung und Einschätzung der Ergebnisse. Wie bereits dargestellt, gehen diese Phasen ineinander über. Falls man zu den Ergebnissen kommt, dass das Modell keine brauchbaren Ergebnisse liefert, wiederholt man die Phasen 1 bis 4.
6. Phase: Deployment / Präsentation
In dieser Phase geht es um die Anwendung der Ergebnisse des CRISP-DM Prozesses. Dabei hängen die Anwendungen von den Fragen und Problemen ab, die behandelt worden sind.
Die Anwendung kann also die Einbindung eines fertigen Modells z.B. in die Produktion oder Automatisierung beinhalten.
Es kann aber auch einfach nur eine Präsentation der Ergebnisse in einem festgelegten Format bedeuten. Dabei kann es sich etwa um eine PowerPoint Präsentation oder einen Blogbeitrag handeln.
Meine Ergebnisse der Datenanalyse zu AirBnB in Berlin habe ich zum Beispiel als Blogbeitrag auf Medium veröffentlicht.
Zusammenfassung: CRISP-DM als Anfang
Der CRISP-DM Prozess eignet ich sehr gut als Start für ein Unternehmensprojekt im Bereich Data Science, denn er gibt einen festen Rahmen für das gesamte Projekt.
Wichtig dabei ist zu verstehen, dass es ein iterativer Prozess ist, der selten vollständig abgeschlossen wird.






{kind=link}
Trackbacks/Pingbacks