

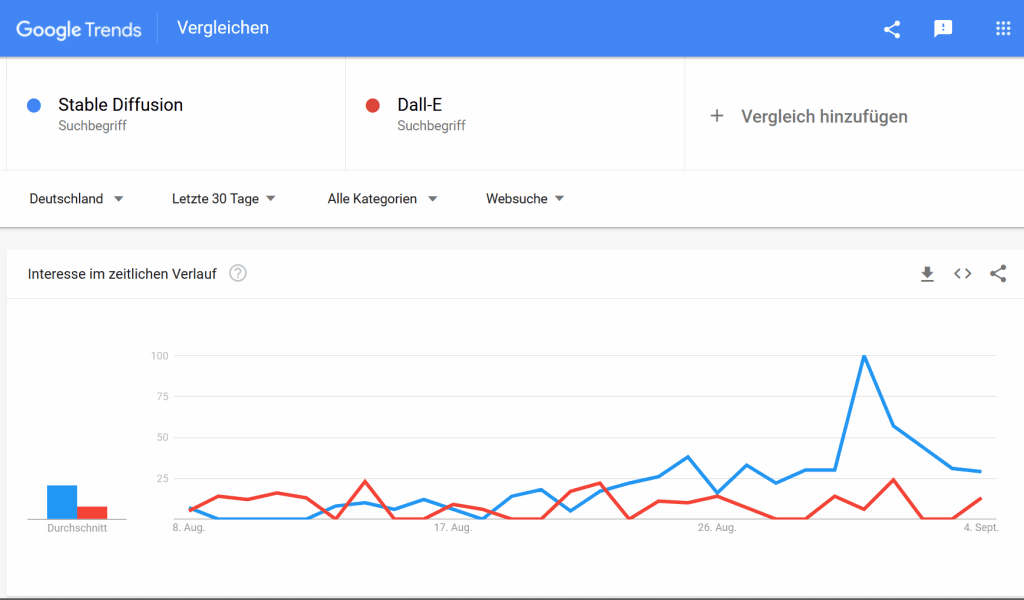
Stable Diffusion gehört zu den neuesten Entwicklungen im Bereich Generative AI. Mit Sturm erobert es Social Media und bald vermutlich auch die Anwendungen im Bereich Kunst und Fotografie. Innerhalb von kürzester Zeit hat Stable Diffusion Modell in Google Suchtrends das Bezahlmodell (DALL-E) überholt. Das liegt sicherlich zum großen Teil daran, dass Stable Diffusion im Gegensatz zu DALL-E open source und somit kostenfrei ist.
Google Suchtrends nach DALL-E (kostenpflichtig) und Stable Diffusion (open source):
Was ist Stable Difussion? Definition
Generative KI
Stable Diffusion gehört zu KI Modellen aus dem Bereich Generative AI (Subform der Künstlichen Intelligenz/Machine Learning). Generative AI erlaubt uns vom Prinzip bereits existierenden Content (Text, Audio, Bild) zu nutzen, um neue Inhalte zu erstellen. Vereinfacht gesagt werden bereits existierende Inhalte als Input für einen Machine Learning Algorithmus benutzt, der als Ergebnis einen neuen Inhalt generiert. Der neue Inhalt sollte dabei plausibel und/oder realitätsnah wirken.
The algorithms begin with models of what a world must be like and then they create a simulated world that fits the model.
Venture Beat
Die bekanntesten Architekturen der Generative KI sind sog. Generative Adversarial Networks (GANs), Auto-Encoder und Transformers.
Generative KI wird oft als Begriff synonym mit Generative Adversarial Networks (GANs) verwendet. Dabei sind GANs nur eine der möglichen Modell-Architekturen für Generative KI. Es gibt diverse andere Architekturen, die sehr schnell an Bedeutung gewinnen. Der Bereich ist sehr dynamisch und man kann davon ausgehen, dass bald weitere Architekturen dazukommen bzw. GANs in ihrer Bedetung überholen werden.
Im Moment sind die GANs die bekannteste Architektur. Ein Beispiel für die Anwendung von GANs ist die Webseite https://thispersondoesnotexist.com/. Sie produziert Bilder von Personen, die in der realen Welt nicht existieren. Das macht sie auf der Basis von Tausenden Bilder existierenden Menschen.
KI-Generiertes Bild:

Eine weitere Architektur, die sehr stark an Bedeutung gewinnt, sind die Transformers. Die Architektur ist im Bereich Natural Language Processing (Sprach-KI) entstanden, wird aber zunehmend auch im Bereich Bild angewandt. Das bekannteste Beispiel sind die Anwendungen von Open AI, wie GPT-3 und DALL-E. Beide Anwendungen basieren auf einer Sprach-Architektur (text-to-image, Transformer), die aus dem Natural Language Processing Bereich kommt. Sowohl DALL-E als auch GPT-3 sind kostenpflichtige Angebote.
Stable Diffusion Definition
Stable Diffusion wurde von stability.ai in Zusammenarbeit mit einigen Institutionen entwickelt. Die Firma produziert verschiedene Open Source Anwendungen. Stable Diffusion ist wohl die bekannteste davon. Ähnlich wie DALL-E generiert Stable Diffusion Bilder. Im Gegensatz zu DALL-E ist Stable Diffusion Open Source und kostenfrei.
Die Modell-Architektur ist die sogenannte text-to-image Architektur. Das heißt, man muss wörtlich beschreiben, was für Bild die KI generieren soll. Stable Diffusion nutzt eine weitere Architekturklasse: Diffusors (Diffusoren):
„Fundamentally, Diffusion Models work by destroying training data through the successive addition of Gaussian noise, and then learning to recover the data by reversing this noising process. After training, we can use the Diffusion Model to generate data by simply passing randomly sampled noise through the learned denoising process.“
AssemblyAI
Vom Prinzip haben Diffusion Modelle ein ähnliches Ergebnis wie andere Generative AI Architekturen: sie generieren neue Inhalte. Eine technische Einführung in die Funktionsweise der Diffusoren kann auf Hugging Face (inklusive Colab Notebook) gefunden werden.
Wie kann ich Stable Diffusion nutzen?
Positiv: Stable Diffusion ist Open Source und somit kostenfrei. Es gibt mehrere Möglichkeiten die Architektur zu nutzen. Die einfachste ist wohl direkt auf der Websiete der Entwicklerfirma StabilityAI. Dort scrollt man etwas nach unten und klickt auf das Angebot Dream Studio.
Clip Drop
Seit April 2023 gibt es (neben dem Dream Studio) eine weitere ofizielle Möglichkeit Stable Diffusion zu nutzen: ClipDrop. Angeboten auch von Stability AI. Man kann via ClipDrop kostenfrei und ohne Anmeldung einige Bilder generieren.
Dream Studio
Um das Angebot zu nutzen muss man sich auf der Webseite mit einer E-Mail-Adresse registrieren. Dream Studio ist vom Prinzip eine Front End Applikation, die uns erlaubt das Modell zu nutzen.
Nach der Registrierung wird man in die Dream Studio Umgebung geleitet. Dort lassen sich diverse Befehle eintippen und der Algorithmus generiert auf dieser Basis ein Bild bzw. Bilder.
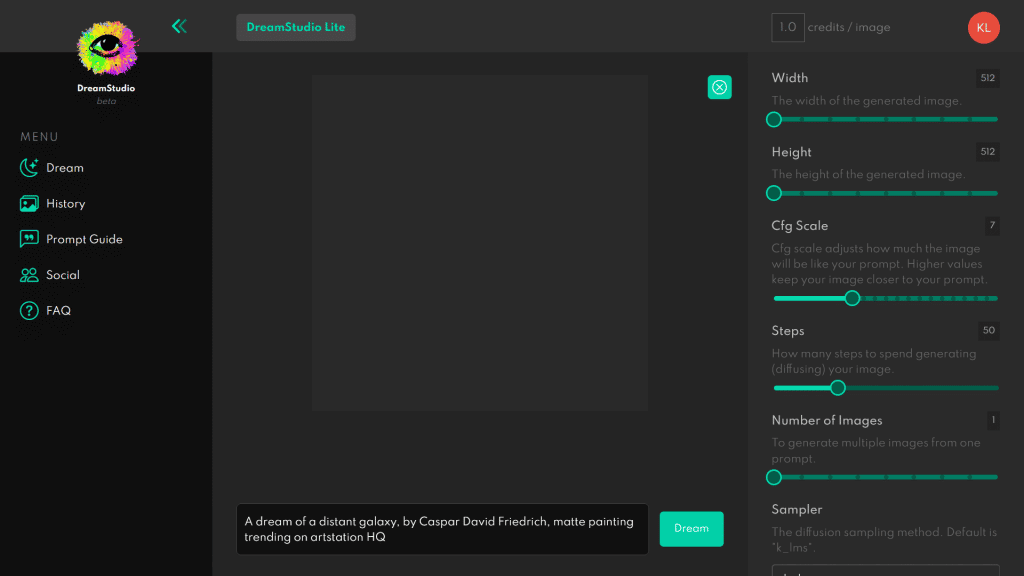
Um gute Ergebnisse zu erzielen ist es sehr empfehlenswert sich durch den Prompt Guide durchzulesen. Die Qualität der Ergebnisse hängt davon ab, wie man mit dem Algorithmus per Textanweisungen kommuniziert. Es ist eine text-to-image Architektur, d.h. man muss entsprechende Wortkombination eingeben, um optimales Ergebnis zu erreichen.
Um beispielsweise ein Bild im Stil eines Malers zu erreichen, sollte man den Namen des Künstlers eingeben. Ich habe zum Beispiel in denPrompt „Angela Merkel Claude Monet“ eingegeben und folgendes Ergebnis erhalten:


Arbeiten mit dem Prompt
Um gute Ergebnisse zu erzielen ist es am Besten in Stichworten zu denken: „Angela Merkel“, „Garten“, „Claude Monet“. Falls das Bild eine Stimmung übermitteln sollte können wir Wörter dazu schreiben, die diese Stimmung beschreiben: „scary“, „happy“. Das Prompt basiert auf Englischer Sprache. Ist etwas zu unscharf, können wir mit den Worten arbeiten, die die Schärfe spezifzieren: „detailed“ .
Am Ende muss man vieles auch ausprobieren. Eine gute Einleitung zum Prompt ist auch hier veröffentlicht worden.
Inspiriert durch ein Tweet von Hardmaru
habe ich die Gleichen Stichworte in den Prompt eingegeben, nur Rihanna durch Angela Merkel ersetzt: „Anime scene of Angela Merkel as a space pilot, Studio Ghibli, high quality, trending on Artstation.“
Das ist mein Ergebnis:

Hugging Face Hub
Stable Diffusion ist auch auf Hugging Face Hub zugänglich. Hugging Face ist eine Firma, die u.a. für die Erstellung der Transformers (Form der KI Architektur) bekannt ist. Sie ist vor allem im Bereich Natural Language Processing aktiv. Auf ihrem Hub erlaubt sie verschiedne KI-Modelle hochzuladen und auszuprobieren.
Hier ein Link zu der Anwendnung. Vom Prinzip funktioniert es ähnlich wie das Angebot von Dream Studio.
Eigener PC
Eine weitere Möglichkeit ist die Stable Diffusion auf den eigenen PC herunterzuladen. HIerzu gibt es auch einige Möglichkeiten. Der PC muss allerdings bestimmte Parameter erfüllen, damit damit der Algorithmus eingespielt werden kann: Speicherkapazität von ca 4-6 VRAM Gigabytes sowie Nvidia GPU.
Um das Modell zum Laufen zu bringen, sollte man in best case Szenario gewisse Vorkenntnisse in Programmiersprachen haben.
Installation (benötigte Software)
Um Stable Diffusion auf dem PC zu instalieren werden folgende Packages benötigt:
- Python
- Git/Github
- Anaconda (optional für manche Anleitungen)
Hier sind die wichtigsten Anleitungen, wie man mit Anaconda und Git arbeitet:
Für Anaconda: „Installing Anaconda on Windows“ (Data Camp) und „getting started with conda“ (conda.io).
Für Github und Git: „Learn the Basic“ (Freecodecamp).
Modell Gewichte (Checkpoint) + Repository installieren
Im nächsten Schritt installieren wir das Stable Diffusion Modell. Wir entnehmen die Modellarchitektur der GitHub Seite und die Modellgewichte (Checkpoints) dem Hugging Face Hub. Es gibt auch weitere Alternativen für das Modell auf Github (hier zum Beispiel). Das Gute an den GitHub Modellen ist, dass sie auf der Webseite immer bereits eine Anleitung zur Installation sowie Anforderungen haben.
Weiter im Text beschreibe ich eine der vielen Möglichkeiten Stable Diffusion auf dem PC zu installieren.
Die Orginal Stable Diffusion Modellarchitektur ist recht groß. Aus diesem Grund gibt es weitere optimierte Versionen, die besser auf einem PC funktioneren, wie zum Beispiel dieses auf GitHub: https://github.com/basujindal/stable-diffusion (erstellt von Basu Jindal). Ich habe diese Version installiert, indem ich rechts oben auf „Code“ und dann auf „Download ZIP“ geklickt habe.
Anweisungen auf Stable Diffusion GitHub Webseite folgen
Weiter befolgen wir Anweisungen auf der GitHub Webseite der urprünglichen Stable Diffusion Architektur: https://github.com/CompVis/stable-diffusion. Unten in der Beschreibung (Requirements) stehen die Eingaben, die wir in das Anaconda Prompt eingeben müssen.
Wir öffnen das Anaconda/Conda Prompt. Wichtig: wir müssen im selben Ordner sein, wie auch das Stable Diffusion Modell (ZIP-Datei). Sobald wir im richtigen Directory sind, tippen wir im Prompt folgende Befehle aus der oben genannten GitHub Webseite ein:
conda env create -f environment.yamlNachdem die Packages heruntergeladen sind (und das dauert eine Weile), können wir das entsprechende Conda Environment aktivieren:
conda activate ldmDanach machen wir weiter mit der Anleitung und kopieren die Anweisung unter „obtaining the stable diffusion original weights“.
Zuerst richten wir einen Ordner (Repository) für die Gewichte/Modell ein:
mkdir -p models/ldm/stable-diffusion-v1/Jetzt werden wir die Weights des Modells aus dem Hugging Face Hub herunterladen. Dazu müssen wir uns erst auf Hugging Face registrieren. Aus der Webseite laden wir die Gewichte: sd-v1-4-ckpt (Link) herunter. Im zweiten Schritt schieben wir die Gewichte in das oben erstellte Directory und bennenen es in „model.ckpt“ um.
Damit das Modell schnell funktioniert, ist es wichtig beim Ausführen „optimizedSD“ zu callen und nicht die orginelle Architektur.
Wir geben deshalb „optimizedSD“ in das Prompt ein. Hier die Veränderte Version, die funktionieren sollte:
python optimizedSD\optimized_txt2img.py --prompt "ein Bild, welches ich zeichnen möchte" --plmsDie Prompt-Veränderung ist auch auf dem Github Profil der verkleinerten Version (Autor Basu Jindal) beschrieben. Die Fotos werden gespeichert in dem Ordner „Outputs“ auf unserem Computer.
Es gibt weitere Möglichkeiten Stable Diffussion auf eigenem PC zu nutzen. Man kann den Code so verändern, dass das Modell kleiner wird. Am Besten ist es ein wenig im Netz zu recherchieren und das Beste für sich auszusuchen.
Diese Videoanleitung auf YouTube ist sehr anschauich: Stable Diffusion on Windows.
Stable Diffusion in Photoshop
Inzwischen gibt es erste Möglichkeit Stable Diffusion im Photshop (Adobe) zu nutzen.
Christian Cantrell hat einen Photoshop PlugIn erstellt. Er kann auf seiner Webseite heruntergeladen werden. Erklärungen zu der Anwendung sind auf seinem Twitter Account zu finden.
Fazit – kostenloser KI- Bildgenerator: Chance und Risko
Stable Diffusion ist die neueste Entwicklung im Bereich Generative KI. Die größten Architekturen/Modelle sind bislang: GPT-3, Dall-E und jetzt auch Stable Diffusion. Dabei ist Stable Diffusion bislang die einzige Open Source Entwicklung im Bereich text-to-image Architektur.
Der Bereich entwickelt sich sehr dynamisch. Im Moment passiert sehr viel in Transformer-basierten Architekturen.
Das Risiko der Open Source Modellen wie Stable Diffusion ist die potentielle Reproduktion des bereits im Datensatz vorhandenen Bias im Hinblick auf die Hautfarbe, Geschlecht und andere Merkmale. Zum Thema von Bias in Algorithmen wurde ein weiterer Beitrag verfasst: Faule Daten führen zu faulen Algorithmen. Bei der Bilderstellung ist es deswegen wichtig das Bewusstsein für den Bias zu entwickeln und entsprechend die Ergebnisse immer zu hinterfragen.
Update: Stable Diffusion kann jetzt nicht nur als PyTorch, sondern auch in TensorFlow/Keras implementiert werden: GitHub-Link.







{kind=link}
Sehr informativer Beitrag, dank für den Impuls;)
Toller Artikel. Ist mit „optimizedSD“ dieses Github Projekt gemeint, welches dann zusätzlich geclont werden muss?https://github.com/basujindal/stable-diffusion/tree/main/optimizedSD
Hallo, ja. es geht um dieses Projekt (optiizedSD=Projekt von Basu Jindal)