
Seit einigen Jahren werden zunehmend Artikel publiziert, die das baldige Überholen der Ärzte und insbesondere Radiologen in der Diagnostik durch KI verkünden.
So schreibt beispielsweise die Zeit:
„Die Fachgesellschaft der US-amerikanischen Radiologen prognostiziert der Radiologie, dass sie sich in den nächsten Jahren entscheidend verändern wird. Der Grund: Die Künstliche Intelligenz (KI) wird Einzug halten. Computer werden den Ärzten Arbeit abnehmen, wohl einfach deswegen, weil sie in Zukunft vieles besser können.“ in „Die Angst des Arztes vor KI.“
Noch hoffnungsvoller schreibt die Webseite futurism.com: „Artificial Intelligence Reads Mammograms With 99% Accuracy.“
Leicht kann hier der Eindrück geweckt werden, dass die KI-Algorithmen längst die Ärzte in der Diagnostik überholt haben.
Diese Hoffnungen werden sich in der näheren Zukunft nicht erfüllen, denn trotz der euphorischen Meldungen, hat die Treffsicherheit der KI-Algorithmen im Diagnostikbereich die Ärzte gar nicht überholt. Zudem funktioniert sie oft nicht zuverlässig. Auch andere Gründe sprechen dagegen. Hier gehe ich auf diese Problematik näher an.
Machine Learning Modelle sind nicht durchgehend zuverlässiger als Radiologen
Algorithmen liefern nicht immer bessere Ergebnisse als Ärzte. Die bisherigen Ergebnisse sind eher durchwachsen.
Hier zitiere ich nochmal den Artikel der Stanford Machine Learning Group, die ein Deep Learning Modell zur Untersuchung von Knochenscans entwickelt hat: „Large Dataset for Abnormality Detection in Musculoskeletal Radiographs“ (hier ein pdf der Studie). In der Untersuchung schnitt der Algorithmus deutlich schlechter als die Radiologen ab. Die Autoren schreiben:
„Model performanceis comparable to the best radiologist performance in detecting abnormalities on finger and wrist studies. However, model performance is lower than best radiologist performance in detecting abnormalities on elbow, forearm, hand, humerus,and shoulder studies.“
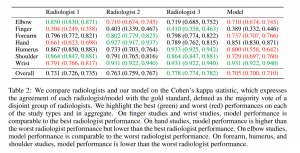
Quelle: Large Dataset for Abnormality Detection in Musculoskeletal Radiographs
Ein weiteres prominentes Beispiel für das Versagen von KI im medizinischen Bereich ist das Scheitern des IBM Watson in der medizinischen Diagnostik. Der Supercomputer von IBM wurde zunächst darauf trainiert das Spiel Jeopardy! zu gewinnen. Nach diesem Erfolg hegten seine Entwickler große Hoffnungen auf weitere Anwendungen für Watson ausserhalb von Spielen. Der Computer spezialisiert sich vom Prinzip in der sprachlichen Musterfindung. Die Forscher setzten den IBM Watson auf Mustererkennung in der Krebsforschung an. Die Hoffnung war, dass IBM Watson besser als medizinisches Personal bestimmte Therapieemfehlungen machen könne. Wie die medizinische Seite STAT jedoch berichtete, musste das Projekt beendet werden, da Watson falsche Therapieformen empfohlen hatte: „IBM’s Watson supercomputer recommended ‘unsafe and incorrect’ cancer treatments, internal documents show.“ (Beitrag kostenpflichtig).
Vor kurzem twitterte auch Anima Anandkumar (Leiterin der Forschung bei Nvidia):
„#AI will not replace radiologists and dermatologists anytime soon. We need new hashtags: #AInotReady #AInotjustDeeplearning“
Sie zitierte aus der neuesten Studie Winker et al (2019) in JAMA Dermatology, die große Mängel der Deep Learning Modelle bei der Erkennung von Hautkrebs zeigte. Offenbar diagnostizierten die Algorithmen deutlich mehr Muttermale als Melanome als Dermatologen:
„In this cross-sectional study of 130 skin lesions, skin markings by standard surgical ink markers were associated with a significant reduction in the specificity of a convolutional neural network by increasing the melanoma probability scores, consequently increasing the false-positive rate of benign nevi by approximately 40%.“
Die Ärzte haben diese Modelle an Menschen getestet, wo die Muttermale zusätzlich mit dermatologischen Markern markiert waren. Dies reichte bereits um die Deep Learning Modelle zu verwirren und ihre Ergebnisse deutlich zu verschlechtern.
Dies bringt uns auch zum nächsten Kritikpunkt.
Genauigkeit ist kein Indikator für gutes Abschneiden von Algorithmen in der medizinischen Diagnostik
Die meisten Beitrage, die positiv über die KI-Studien in der medizinischen Diagnostik berichten, nutzen die Genauigkeit bzw. Accuracy als Maßstab für das Abschneiden der KI-Algorithmen im Vergleich zu Radiologen.
Die Genauigkeit ist allerdings der falsche Maßstab, um den Erfolg der Künstlichen Intelligenz im medizinischen Bereich zu bewerten, denn sie sagt nichts über die Rate der falsch positiven und falsch negativen Fälle aus. Zu dieser Problematik habe ich bereits einen Beitrag geschrieben. In der Diagnostik kommt es nicht so sehr auf die Genauigkeit an, sondern auf den Anteil der falsch positiven und falsch negativen, denn dieser kann bei einer Genauigkeit von 99% trotzdem ziemlich groß sein. Beispielsweise können bei einer 99% Genauigkeit trotzdem von 1 000 000 Menschen 999 900 von einem Test als krank eingestuft werden (die sogenannten falsch positiven), obwohl sie gesund sind.
Aus diesem Grund werden für die Diagnostik und auch in anderen Bereichen, wo die menschliche Sicherheit höchste Priorität hat, weitere Messwerte zur Bewertung der Algorithmen herangezogen.
Im Bereich der medizinischen Diagnostik wäre der Recall die richtge Wahl. Der Recall misst die Anzahl der echten positiven. D.h. es ist ein guter Messwert für Modelle, die wenig falsch negative Resultate beinhalten sollen. Die Zahl der falsch negativen beinhaltet kranke Menschen, die durch den Algorithmus als gesund eingestuft worden sind. Den Recall-Messwert klein zu halten geschieht meistens auf Kosten der Präzision: die Zahl der falsch positiven ist dann größer, denn sie ist mit kleineren Kosten verbunden als die falsch negativen. Beispielsweise wäre es bei einem Ausbruch der Ebola sinvoller mehr Patienten als krank einzustufen als umgekehrt eine größere Zahl von Kranken ohne Behandlung entlassen.
Es spielt also keine Rolle was für Genauigkeit ein neuer Ebolatest hat, wenn er einen hohen Recallmesswert aufweist und viele Menschen ohne Behandlung als nicht infiziert laufen lässt, die aber tatsächklich erkrankt sind, und dann möglicherweise weitere Menschen anstecken.
Aber auch die Zahl der falsch positiven spielt eine Rolle. Vor kurzem erreichte mich auch folgende Meldung: der MIT Professorin Regina Barzilay ist es gelungen einen Deep Learning Modell zu erstellen, das anhand von Mammographienbildern erkennen kann, ob ein Mensch an Brustkrebs erkankt – und zwar 5 Jahren VOR der eigentlichen Erkrankung. Dies an sich ist eine wunderbare Nachricht. Allerdings beträgt die Accuracy rate bei diesem Algorithmus nur 31%. Dies bedeutet, dass 31% der Patienten vom Algorithmus korrekt klassifizert wurden. Allerdings sagt dieser Wert nichts darüber aus, wieviele falsch positive und flasch negative Diagnosen das Modell beinhaltet. Es kann also durchaus sein, dass der Algorithmus sehr viele Frauen als falsch positiv einstuft (d.h. positiv obwohl in der Realität gesund). Dies würde für diese Frauen großen Stress bedeuten. Sie würden womöglich zur weiteren Untersuchungen eingeladen, die an sich auch nicht ohne Nebenwirkungen sind. Man könnte also diesen Algorithmus in der Praxis gar nicht anwenden.
All diese Gründe sprechen nicht dafür, dass die KI bald die Ärzte ersetzen wird. Optimal können wir auf eine Unterstützung in der medizinischen Diagnostik hoffen, die vielleicht das erste Screening der Patienten durchführt. Dies an sich wäre schon ein wichtiger Fortschritt, der allerdings nichts mit den futuristischen Meldungen in den Medien zu tun hat.







{kind=link}
Hi Alex, endlich habe ich Zeit gefunden mir das Account anzuschauen und tatsächlich gibt es auf dem Account einige Unregelmäßigkeiten.…
Hallo, ich werde mir das Profil angucken und poste hier, was ich gefunden habe. Ich brauche aber noch ca. Eine…
Hi Aleksandra, ich glaube, mit deiner Analyse könntest du vielen Menschen helfen, die betrogen werden. Insbesondere in der Krypta-Welt. Dort…
Größerer und allumfassender Algorithmus: Die Schwerkraft ist keine Kraft, die von A nach B reicht, sondern ein grundlegendes und elementares…
Hallo, ja. es geht um dieses Projekt (optiizedSD=Projekt von Basu Jindal)