

Was genau sind neuronale Netze?
Kurz gesagt: Deep Learning ist eine Methode im Bereich des maschinellen Lernens, die auf künstlichen neuronalen Netzen beruht. Bei deren Entwicklung ließen sich die Forscher von menschlichen neuronalen Netzen inspirieren.
Vom Prinzip geht es bei Deep Learning um die Lösung von folgenden Aufgaben:
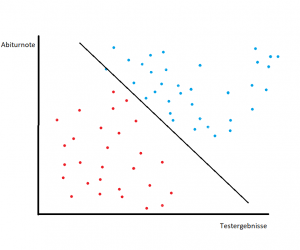
Deep Learning Aufgabe
Die Grafik zeigt die Verteilung von Schülern je nach Abiturnoten und Testergenbnissen. Die Schüler haben Abiturnoten bekommen sowie eine Eingangsprüfung für eine Uni geschrieben, wo sie auch benotet wurden. Die Verteilung zeigt, welche Schüler die Zulassung für die Uni bekommen haben (blau) und welche nicht (rot).
Die Aufgabe eines Deep Learning Modells in diesem Fall ist eine Linie (hier: schwarz) zu zeichnen, die die Schüler bestmöglich trennt. Die Linie minimiert sozusagen Fehler, die bei dieser Klassifizierung entstehen. Auf der Basis dieser Berechnungen ist es als Folge möglich, anhand von Noten vorauszusagen, ob ein Schüler die Zulassung erhält oder nicht – mit genaueren Wahrscheinlichkeitsangaben.
Das gesamte Deep Learning Model sieht dann in der komplexeren Version wie ein Netz aus, welches viele solche Berechnungen miteinander verbindet:
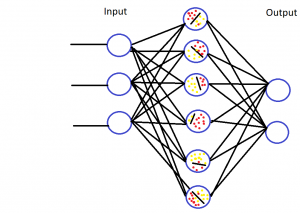
Das Prinzip ist das Gleiche: es geht um die gelben und roten Punkte in den Kreisen. Das erklärte Ziel des Rechners ist eine perfekte Trennung zwischen den roten und den gelben Punkten zu zeichnen. Mittels mathematischen Berechnungen (Regressionen) versucht der Computer die Linie so zu führen, dass die Fehler minimal sind.
Input – Hidden Layer – Output
Der Aufbau der neuronalen Netze folgt dem Schema: Input – Hidden Layer – Output. Zunächst kriegt der Computer Input in Form von Daten. Diese Daten werden dann in den sogenannten hidden Layers weiterverarbeitet. Dort passieren dann die Berechnungen, die ich oben grafisch dargestellt habe. Danach wirft der Computer irgendein Ergebnis. Output.
Gute Videos zum Thema Deep Learning
Luis Seranno (Data Scientist und Lehrer @Udacity) hat auf Youtube geniale Videos veröffentlicht, die Maschinelles Lernen und Deep Learning sehr gut und visuell erkären. Hier Links zu den Videos:
Luis Serrano: A Friendly Introduction to Machine Learning @Youtube
Luis Serrano: A friendly introduction to Deep Learning and Neural Networks @Youtube
Deep Learning passiert nicht „von alleine“
Zu den Legenden gehört, dass die Computerberechnungen „ganz alleine“ in einer Art „Black Box“ passieren. Das stimmt einfach nicht.
Zum einen muss man bei diesen Modellen eine ganze Menge Parameter einstellen, damit die Berechnungen fehlerfrei laufen, sonst wird das Modell nicht funktionieren.
Zum anderen ist es eben keine „back box“. Es ist mathematisch nachvollzeihbar, was der Computer im Rahmen dieser Berechnungen macht, verallgemeinert gesprochen versucht er eben die Punkte mittels dieser Linien fehlerfrei zu klassifizieren.
Vortrainierte Modelle
Generell werden die Deep Learning Modelle in der Praxis nie von grundauf neu gebaut. Man nutzt vorgefertigte Modelle und baut nur den letzten Teil dieses Modell um.
Für Bilderkennung nutzt man zum Beispiel folgende vortrainierte Modelle:
resnet, alexnet, vgg, squeezenet, densenet, inception
Die vortrainierten Modelle performen besser, auch wenn man sie für eigene Daten anwendet. Mehr zu den oben genannten Arichtekurten schreibt die ofizielle Anleitung auf der PyTorch webseite.
Umsetzung in Python: PyTorch vs TensorFlow
In Python gibt es zwei Bibliotheken, die sich Deep Learning widmen: TensorFlow (von Google entwickelt) und PyTorch (von Facebook entwickelt).
TensorFlow wird häufiger im industriellen Bereich angewandt während PyTorch im Bereich Data Science häufiger Anwendung findet. Generell ist TensorFlow weiter verbeitet als PyTorch. Allerings ist es für einen Data Scientist oder Analysten, der Erfahrung mit Python hat, viel leichter zuerst mit PyTorch anzufangen. Vorteil von PyToch ist auch, dass er NumPy arrays direkt konvertieren kann.
Ich persönlich habe bislang nur mit PyTorch gearbeitet. Ehrlicherweise finde ich die Deep Learning Anwendungen in Python generell relativ schwer. Vor allem, wenn man nicht gerade ein erfahrener Python Programmierer ist. Mit Blick auf die Zukunft muss man sagen, dass die Sperrigkeit dieser Anwendungen in Python eine große Hurde für die breite Anwendung in der Praxis darstellt.
Konkrete Anwendungen / Use Cases für Deep Learning
Tierklassifizierung: Hund oder Katze?
Ein Ziel für die Anwendung von Deep Learning könnte sein, verschiedene Bilder von Hunden und Katzen zu trennen und erkennnen, ob es sich dabei um Hund oder Katze handelt.
Blumensorten: Tulpe oder Rose?
Ein Projekt, an dem ich gearbeitet habe, hatte als Ziel Blumensorten korrekt zu klassifizieren. Der Datensatz bestehend aus vielen Fotos von Blumen und wurde zunächst getrennt in drei Teile:
Learning-Teil: an diesem Teil der Fotos „lernte“ der Rechner die Blumensorten zu erkennnen.
Der Validierungsteil diente der Überprüfung, ob der Rechner die Blumen richtig klassifiziert. Als letztes kam dann der Testset der Bilder, an dem getestet wurde, ob die Klassifizierung funktioniert.
Medizin: Tumorerkennung
Ein konkreters Beispiel für die Anwednung von Deep Learning wäre die Klassifizierung von Röntgenbildern zwecks Tumorerkennung. Diese Modelle sind bislang nur in der Forschungsphase und es sieht leider bislang nicht gut aus für diese Modelle. Der Bereich Machine Learning ist genauso anfällig für eine Reproduzierbarkeitskrise wie anderen wissenschaftlichen Studien. Hier mehr zu diesem Thema.
Probleme mit Deep Learning
Trotz vieler Erfolge wird Deep Learning große Schwierigkeiten haben, sich in der Praxis durchzusetzen. Einer der Gründe dafür ist die bereits genannte Sperrigkeit in der Anwendung. Es gibt allerdings andere Gründe, die noch schwerer auf der Zukunftsfähigkeit der Deep Learning lasten.
Eines dieser Probleme ist die Tatsache, dass neuronale Netze beschriftete Daten, sog. labeled data benötigen. In der Praxis führt das dann dazu, dass die Forscher sich auf die Aufgaben fokussieren, wo die Beschriftung der Daten relativ einfach ist. Dies sind nicht unbedingt die Fälle, die Praxisrelevanz haben.
Ein weiteres Problem mit Deep Learning liegt in der Tatsache, dass diese Modelle gut unter Laborbedingungen funktionieren, sobald es aber an die Praxis in der realen Welt geht, versagen sie häufig mit der Klassifikation. Zum Beispiel, wenn der Blickwinkel auf dem Foto anders ist, kann das Modell den Gegenstand auf dem Foto nicht mehr erkennen.
Bislang können diese Modelle daher nur in sehr speziellen Umgebungen, wie eben Röntgenaufnahmen, industrielle Produktion, bestehen. Sobald es jedoch um die Anwendung in komplexen Situationen, wie z:B. selbstfahrende Autos, geht, versagen sie bislang ziemlich zuverlässig.
Ähnlich sieht es aus, wenn sich im Foto der Kontext ändert. Im Artikel „Limitations of Deep Learning for Vision, and How We Might Fix Them“ von Alan Yuille und Chanxi Liu beschreiben die Autoren einen konkreten Fall: wenn man einem Affen eine Guitarre per Photshop hinzufügt, denkt Deep Learning, dass es sich auf dem Foto um einen Menschen handelt.
Ein weiteres Problem stellt die benötigte Rechenkraft. Um zuverlässig zu funktionieren benötigt Deep Learning große Rechenpower, die nicht jede Firma bereitstellenkann.
Zusammenfassung
Bislang tun sich die neuonalen Netze jedoch damit schwer, Sachen in einer komlexeren Umgebung zu erkennen, was deren Anwenungen auf nur kleine kontrollierte Fälle zulässt. Zudem ist die Rechenkraft, die so ein Modell benötigt, nicht immer gegeben.
Dies veranlasst viele Forscher inzwischen dazu, Deep Learning nur als Teil einer größeren Lösung zu sehen, die auch andere Methoden umfasst, die etwa Datenstrukturen und ihre logischen Verknüpfungen berücksichtigen. Dazu werde ich demnächst einen weiteren Beirtag schreiben.





{kind=link}
Hello, after reading this awesome post i am also glad to share my
knowledge here with friends.