

In dieser Beitragsreihe werden wir nach und nach die wichtigsten Algorithmen für Machine Learning vorstellen.
Die Unterscheidung zwischen Supervised und Unsupervised Learning ist am besten vom praktischen Standpunkt zu verstehen. Mal angenommen wir haben einen großen Datensatz, den wir gerne mit Hilfe von Machine Learning analysieren möchten.
In diesem Fall ist eine der ersten Fragen, die nach dem Datensatz: sind die Daten in unserem Datensatz beschriftet (labeled) oder unbeschriftet (unlabeled)?
 In diesem Fall sind es einfach Bilder der Blumen. Wir wissen dabei nicht, um welche Blumen es sich dabei handelt. Wir müssen diese Bilder/Daten erst entweder selbst beschriften oder aber einen Algorithmus anwenden, der die Daten für uns beschriften wird. Damit landen wir im Bereich von Unsupervised Learning, welcher sich mit unbeschrifteteten Daten beschäftigt.
Wenn unser Datensatz aber wie folgt ausschaut:
dann handelt es sich in diesem Fall um beschriftete Daten (sog. labeled data). In diesem Fall können wir bereits mit den Algorithmen aus der Supervised Learning Kiste fortfahren.
Innerhalb des Supervised Learnings unterscheiden wir eine weitere wichtige Kategorisierung, die mit dem Datensatz zusammenhängt. Je nachdem ob unsere Daten kategorisch oder kontinuierlich sind, unterscheiden wir zwischen zwei Arten von Supervised Learning Algorithmen: Klassifikations- und Regressionsalgorithmen.
https://datenverstehen.de/machine-learning-einfach-erklaert
In diesem Fall sind es einfach Bilder der Blumen. Wir wissen dabei nicht, um welche Blumen es sich dabei handelt. Wir müssen diese Bilder/Daten erst entweder selbst beschriften oder aber einen Algorithmus anwenden, der die Daten für uns beschriften wird. Damit landen wir im Bereich von Unsupervised Learning, welcher sich mit unbeschrifteteten Daten beschäftigt.
Wenn unser Datensatz aber wie folgt ausschaut:
dann handelt es sich in diesem Fall um beschriftete Daten (sog. labeled data). In diesem Fall können wir bereits mit den Algorithmen aus der Supervised Learning Kiste fortfahren.
Innerhalb des Supervised Learnings unterscheiden wir eine weitere wichtige Kategorisierung, die mit dem Datensatz zusammenhängt. Je nachdem ob unsere Daten kategorisch oder kontinuierlich sind, unterscheiden wir zwischen zwei Arten von Supervised Learning Algorithmen: Klassifikations- und Regressionsalgorithmen.
https://datenverstehen.de/machine-learning-einfach-erklaert
Labeled vs Unlabeled Data
Die unbeschrifteten Daten (sog. unlabeled Data) siehen beispielsweise folgendermaßen aus: In diesem Fall sind es einfach Bilder der Blumen. Wir wissen dabei nicht, um welche Blumen es sich dabei handelt. Wir müssen diese Bilder/Daten erst entweder selbst beschriften oder aber einen Algorithmus anwenden, der die Daten für uns beschriften wird. Damit landen wir im Bereich von Unsupervised Learning, welcher sich mit unbeschrifteteten Daten beschäftigt.
Wenn unser Datensatz aber wie folgt ausschaut:
In diesem Fall sind es einfach Bilder der Blumen. Wir wissen dabei nicht, um welche Blumen es sich dabei handelt. Wir müssen diese Bilder/Daten erst entweder selbst beschriften oder aber einen Algorithmus anwenden, der die Daten für uns beschriften wird. Damit landen wir im Bereich von Unsupervised Learning, welcher sich mit unbeschrifteteten Daten beschäftigt.
Wenn unser Datensatz aber wie folgt ausschaut:
 dann handelt es sich in diesem Fall um beschriftete Daten (sog. labeled data). In diesem Fall können wir bereits mit den Algorithmen aus der Supervised Learning Kiste fortfahren.
dann handelt es sich in diesem Fall um beschriftete Daten (sog. labeled data). In diesem Fall können wir bereits mit den Algorithmen aus der Supervised Learning Kiste fortfahren.
Unsupervised Learning (Unüberwachtes Lernen)
Dieser Teilbereich von Machine Learning beschäftigt sich mit den unbeschrifteten Daten. Im Unsupervised Learning geht es vom Prinzip darum aus den unbeschrifteten Daten so viele Informationen wie möglich zu extrahieren. Der Ausgangspunkt ist oft ein unsortierter und unbeschrifteter Datensatz, den wir mit Hilfe von Unsupervised Learning bearbeiten, um Informationen und Merkmale zu extrahieren. Grundsätzlich ist es schwieriger mit unbeschrifteten Daten und somit auch mit Unsupervised Learning zu arbeiten. Oft müssen im Vorfeld bereits bestimmte Paramter geschätzt oder angenommen werden. Es gibt hierzu oft keine Vorgaben und keine Orientierungspunkte. Im Beispiel mit den unbeschrifteten Blumensorten könnte ein Unsupervised Learning Algorithmus die Blumensorten ordnen. Hier beginnen aber bereits die Probleme, denn nach welchen Kritereien sollen die Bilder geordnet werden? Die meisten Unsupervised Learning Algorithmen ordnen die Daten nach Ähnlichkeit. Dabei kann die Ähnlichkeit auf verschiedene Art und Weise berechnet werden Grundsätzlich unterscheiden wir folgende Unsupervised Learning Methoden:Clustering Algorithmen
Diese Algorithmen grupieren die Daten in die sogenannten Clusters. Die Gruppen der ähnlichen Daten werden bestimmten Clustern zugeordnet. Zu den bekanntesten Clustering Algorithmen gehören: k-Means und DBSCAN.Dimensionality Reduction (Dimensionsreduktion) Algorithmen
Die Dimensionality Reduction Algorithmen vereinfachen unsere Daten. Sie kommen oft zum Einsatz, wenn ein Datensatz sehr viele Variablen bzw Features hat. In diesem Fall lässt sich die Variablenzahl mit Hilfe von Dimensionsreduktion verkleinern. Zu den bekanntesten Dimensionality Reduction Algorithmen gehört die PCA (Principal Component Analysis).Generative Algorithmen
Generative Algorithmen generieren neue Datenwerte, die eine Ähnlichkeit mit den bereits bestehenden Daten haben. Hier sind die sogenannten Generative Adversarial Networks die populärsten Methoden. In der Praxis werden die Unsupervised Learning Algorithmen oft im Vorfeld einer Datenanalyse angewandt, um eine Struktur in Big Data zu bringen. Mit Hilfe von Dimensionsreduktion kann man die Anzahl der Variablen verringern. Im Anschluss werden die gängigen Algorithmen aus dem Supervised Learning angewandt. Clustering Algorithmen werden oft im Markt verwendet, um beispielsweise mehr über Kunden zu erfahren (Kundensegmentierung).Supervised Learning (Überwachtes Lernen)
Supervised Learning ist der Teilbereich des Machine Learning, der mit beschrifteten Daten (sog. labeled data) arbeitet. Bei beschrifteten Daten handelt es sich oft um eine „klassische“ Datenform wie zum Beispiel Excel Tabellen. Supervised Learning (oder auch auf Deutsch Überwachtes Lernen) ist der populärste Teilbereich des Machine Learning. Viele populäre ML-Anwendungen basieren auf Supervised Learning Algorithmen. Die Supervised Learning Algorithmen bearbeiten die Daten auf klassische Art und Weise. Das Modell speichert die Informationen aus dem Datensatz ein. Im Anschluss forumliert es die Regeln, die den Daten entsprechen und schätzt die Ergebnisse.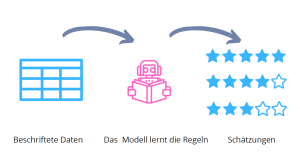 Innerhalb des Supervised Learnings unterscheiden wir eine weitere wichtige Kategorisierung, die mit dem Datensatz zusammenhängt. Je nachdem ob unsere Daten kategorisch oder kontinuierlich sind, unterscheiden wir zwischen zwei Arten von Supervised Learning Algorithmen: Klassifikations- und Regressionsalgorithmen.
Innerhalb des Supervised Learnings unterscheiden wir eine weitere wichtige Kategorisierung, die mit dem Datensatz zusammenhängt. Je nachdem ob unsere Daten kategorisch oder kontinuierlich sind, unterscheiden wir zwischen zwei Arten von Supervised Learning Algorithmen: Klassifikations- und Regressionsalgorithmen.
Klassifikationsalgorithmen
Die Klassifikationsalgorithmen arbeiten mit Daten, die kategorisch sind. Kategorische Daten haben zwar auch numerische Werte, beschreiben aber eher einen Zustand/Merkmal, wie zum Beispiel: Blumensorten: Rose, Tulpe, Vergissmeinnicht oder ein Geschlecht. Sie grupieren die Daten in bestimmte Kategorien bzw. Werte. Basierend auf diesen Daten liefern die Klassifikationsmodelle Ergebnisse, die die Datenpunkte zu den Kategorien zuordnen. Ein Klassifikationsalgorihmus würde zum Beispiel anhand von verschiedenen biologischen Merkmalen bestimmen, ob die Person die Krankheit X hat oder nicht. Der Output von Klassifikationsmodellen kann sich auf einfache entweder/oder Fragen beschränken, wie eben krank oder nicht krank. Er kann aber auch mehrere Werte als Output umfassen, was bei den Bilderkennungsalgorithmen der Fall ist. Zu den bekanntesten Modellen im Bereich Klassifikation gehören: Naive Bayes, Logistic Regression und Random Forest (kann auch für Regressionsprobleme angewandt werden). Praktische Anwendung finden die Klassifikationsalgorithmen u.a. bei der Stimmungsanalyse oder eben bei Bilderkennungsapps sowie im medizinischen Bereich.Regressionsalgorithmen
Regressionsmodelle arbeiten mit kontinuierlichen numerischen Werten. Der Output eines Regressionsmodells ist ein numerischer Wert, wie zum Beispiel der Produktpreis. Das klassische Beispiel für Schätzungen eines Regressionsalgorithmus sind Immobilienpreise. Auf Kaggle gibt es sehr viele Case Studies mit Regreissionsmodellen, die Immobilienpreise als Datensatz verwenden (z.B. Boston Housing Prices-Datensatz). Es gibt sehr viele Arten von Regressionsalgorithmen, unter anderem: Lineare Regression, Ridge und Lasso Regression) oder Random Forest. In der Praxis wird Regression oft bei Fragestellungen rund um die Preisentwicklung (wie Immobilienpreise, Finanzmarkt) angewandt.Welcher Algorithmus passt zu welchen Daten?
Die Typisierung von ML Algorithmen bietet zugleich eine wichtige Entscheidugshilfe bei der Suche nach dem richtigen Algorithmus für die gegebene Fragestellung und den dazugehörigen Datensatz. Folgender Entscheidungsbaum bildet den Prozess ab: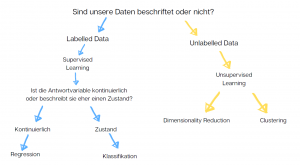
Zusammenfassung
Was sind die wichtigsten Unterschiede zwischen Supervised Learning und Usupervised Learning auf einen Blick? https://datenverstehen.de/machine-learning-einfach-erklaert
https://datenverstehen.de/machine-learning-einfach-erklaert






{kind=link}
Trackbacks/Pingbacks