

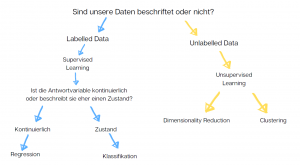
Im vorherigen Beitrag haben wir eine der wichtigsten Klassifizierungen der ML Algorithmen kennengelernt: die Teilung in Unsupervised und Supervised Learning.* Heute geht es um eine weitere Spezialisierung von Machine Learning Methoden im Bereich von Supervised Learning und zwar Regression und Klassifikation.
Supervised Learning Algorithmen arbeiten mit beschrifteten Daten (sog. labeled data). Je nach Art der beschrifteten Daten unterscheiden wir zwei Arten der Supervised ML Algorithmen: Regressionsalgorithmen und Klassifikationsalgorithmen.
Welchen von beiden wir für unsere Daten anwenden, hängt wiederum stark von den Outputs, die unsere Modelle liefern sollen.
Klassifikationsalgorithmen
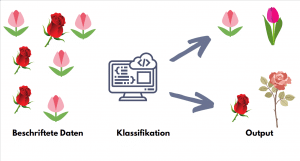
Wenn der Ouptut des ML Modells in Kategorien bzw. wenigen Gruppierungen darstellbar sein soll, nutzen wir die Klassifikation.
Klassifikationsalgorithmen liefern (vereinfacht gesagt) Output in Kategorien und nicht in kontinuierlichen Zahlen.
Anwendung in der Praxis
In der Praxis wird die Klassifikation beispielsweise für die Spam-Erkennung eingesetzt. In diesem Fall haben wir zwei Kategorien: Mail/Spam. Ähnlich kann eine Bilderkennungsapp, die Pilzarten erkennt, auch mit Hilfe von Klassinfikationsalgorithmus gebaut werden. In der medizinischen Diagnostik kommen auch oft Klassifikationsalgorithmen zum Einsatz (Krank/Nicht Krank).
Die populärsten Modelle im Bereich Klassifikation
Zu den populärsten in der Praxis angewandten Klassifikationsalgorithmen gehören Naive Bayes, Random Forest und Logistic Regression. Beide Algorithmen (insbesondere Naive Bayes) sind relativ schnell und funktionieren gut als erste Anwendung.
Logistic Regression (Logistische Regression) wird oft in der binären Klassifikation angewandt d.h., wenn nur zwei Optionen als Output möglich sind. Logistische Regression gehört zu den schnelleren und effizienteren Algorithmen. Aus diesem Grund wird sie oft als ein Startpunkt auf der Suche nach optimalen Modellen angewandt. Da sie binäre Fragestellungen klassifiziert, wird sie u.a. in der Spamerkennung angewandt.
Naive Bayes oder Random Forest können auch für Probleme mit mehreren Outputs (Multiclass-Klassifikation) angewandt werden.
Dabei hat aber der Naive Bayes Klassifikator eine ganze Reihe von Anforderungen, die in der Praxis selten erfüllt werden. Unter anderem verlangt Naive Bayes, dass die Input Features (Variablen) unabhängig voneinander sind. Dennoch funktioniert er relativ zuverlässig und liefert sehr gute Ergebisse mit einer kurzen Rechendauer.
Random Forest Klassifikator baut auf einem schwächeren Algorithmus (Decison Trees) auf. Vereinfacht gesagt werden hier die Outputs mit Hilfe Entscheidungsbäumen berechnet. Eine lange Zeit war Random Forest einer der populärsten Algorithmen im Bereich Data Science. Vor kurzem wurde er von XGBoost abgelöst.
Regressionsalgorithmen
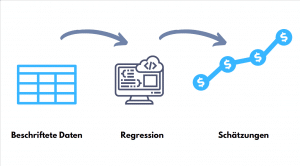
Im Gegensatz zu den Klassifikationsalgorithmen besteht der Modell-Output der Regressionsalgorithmen nicht aus wenigen Kategoriengruppen, sondern aus kontinuierlichen Zahlen. Regressionsalgorithmen schätzen (vereinfacht gesagt) kontinuierliche numerische Werte.
Anwendung in der Praxis
Aus diesem Grund werden die Regressionsalgorithmen für Probleme mit sehr vielen numerischen Outputs angewandt, wie zum Beispiel die Schätzung von Immobilienpreisen in einem Viertel, Börsenpreisentwicklung, Einkommen usw.
Die populärsten Regressionsmodelle
Generell wird die klassische lineare Regression in ihrer Grundform selten angewandt. Meistens wird sie je nach verschiedenen Anforderungen in die Lasso oder Ridge Regression abgewandelt. Für komplexere Zusammenhänge wird auch die Polynomiale Regression angewadndt. Zudem kann auch Random Forest als Regressionsalgorithmus implementiert werden (Random Forest Regression).
*Manchmal muss man Methoden aus dem Bereich Supervised und Unsupervised Learning kombinieren und dann spricht man über Semi-Supervised Learning.







{kind=link}
Toller Beitrag, herzlichen Dank!