

Nachdem mein vorheriger Beiträg das Deep Learning erklärt hat, ist es an der Zeit das übergreifende Konzept des maschinellen Lernens darzustellen, und zwar ohne dabei in die komplexeren mathematischen Prinzipien zu verfallen.
Grundsätzlich geht es beim Machine Learning (ML) um das Bauen mathematischer Modelle mit dem Ziel der Datenanalyse / Datenverarbeitung. Die Interpretation der Daten kann dann als eine Visualisierung erfolgen oder aber eine bestimmte Anwendung sein, wie zum Beispiel eine Gesichtserkennungs-App. Das Wekzeug, mit dem man die Daten bearbeitet, ist der Rechner.
„Machine Learning is the sicence and art of programming computers so they can learn from the data“
Aurélien Géron*
Das Maschinelle Lernen wird über diverse und je nach Modell verschiedene Parameter gesteuert.
Im ersten Schritt werden die Parameter eingestellt und auf Trainingsdaten und Validierungsdaten erprobt. Wenn sie gut funktionieren wird so ein Modell auf den Testdaten getestet und dann im besten Fall in die Produktion aufgenommen und in der realen Welt angewandt. Es ist vom Prinzip ein iterativer Prozess der Modellanpassung, so dass das Modell als Folge optimal in der Praxis funktionieren kann.
Kategorien des maschinellen Lernens
Machine Learning kann in drei Kategorien unterteilt werden: supervised machine learning, unsupervised machne learning und reinfocement learning. Dabei können sich diese Kategorien vermischen.
Supervised Machine Learning
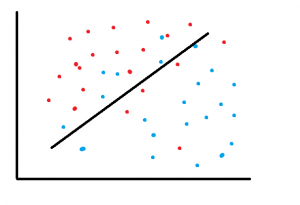
Im Falle des supervised machine learning werden die Daten zunächst beschriftet und erst dann in ein ML Modell eingespeist. Es handelt sich um sogenannte labeled Data. Das Modell wird an den beschrifteten Daten trainiert und erst im zweiten Schritt an den nichtbeschrifteten Daten getestet.
Klassifikation vs. Regression
Supervised ML Modelle können weiter eingeteilt werden in: Klassifikationsalgorithmen und Regressionsalgorithmen.
Im Fall der Klassifikation teilt der Algorithmus die Ergebnisse in diskrete Kategorien ein, zum Beispiel: er wird die Wahrscheinlichkeit berechnen, ob auf dem Bild ein Hund oder eine Katze zu sehen ist.


Auf diese Art und Weise funktioniert zum Beispiel der Deep Learning Algorithmus.
Regressionsalgorithmen liefern dagegen Ergebnisse, die kontinuierlich sind. Ein Beispiel wäre die Ermittlung der Immobilienpreise, je nach Stadtviertel und Anzahl der Zimmer.
Unsupervised Machine Learning
Beim Unsupervised Learning werden die Daten unbeschriftet (unlabeled) dem Algorithmus präsentiert. Hier gibt es zwei Sorten von Algorithmen: clustering und dimensionality reduction Algorithmen.
Clustering vs. Dimensionality Reduction
Der Clustering Algorithmus, wie der Name bereits sagt, identifiziert (nach bestimmten Eigenschaften) Datenansammlungen.
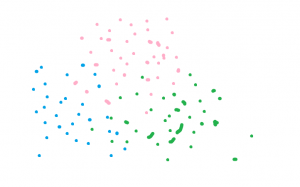
Der Dimensionality Reduction Algorithmus reduziert die Dimensionen der Daten. Diese Methode kann helfen, wenn der Datensatz sehr viele Variablen hat.
Bei 200 ode rmehr Variablen ist eine einfache Datenanalyse nicht mehr möglich. Hier wäre eine Reduktion der Dimension des Datensatzes hilfreich. Genau dies macht der Dimensionality Reduction Algorithmus. Er bildet aus den vorhandenen 200 Variablen eine kleinere Menge an Variablen zum Beispiel: neue 50 Variablen. Sie werden nach bestimmten mathematischen Eigenschaften miteienander kombiniert.
Reinforcement Learning
Reinforcement Learning ist auch eine der Methoden des machinellen Lernens, die zur Zeit in Data Science Kreisen sehr viel Beachtung findet. Dies liegt vor allem an der großen Publicity für diese Methode durch Googles DeepMind Forschung. Mit dem durch Reinforcement Learning trainierten Rechner AlphaGo gelang es dem Google AlphaGo den menschlichen Weltmeister in dem komlpexen chinesischen Spiel Go zu bezwingen.
Das Reinfocement Learning imitiert das menschliche Lernen, indem es dem Rechner erlaubt Handlungen vorzunehmen und dann die Folgen davon zu erfahren. Der Computer lernt also durch die Interaktion mit seinem Umfeld. Dieses Lernen wird durch ein Belohnungssystem eingeführt. Der Rechner wird darauf programmiert die maximale kummulative Belohnung zu erhalten. Eine weitere noch ausführlichere Definition von Reinforcement Learning gibt es bei FreeCodeCamp.
Das Problem von Reinforcement Learning liegt allerdings in der benötigen Rechenkapazität, die auch Deep Learning Algorithmen weit übersteigt. Insofern ist das Reinforcement Learning bislang (noch?) nicht wirklich praktikabel.
Zusammenfassung
Ich hoffe mit der kurzen Zusammenfassung des machinellen Lernens einen schnellen Überblick über die verschiedenen Methoden verschafft zu haben. Weitere Beiträge speziell zu den spezifischen Disziplinen mit konreten Beispielen und Anleitungen werden noch folgen.
Wichtig ist noch anzumerken, dass das Machine Learning nur einen Teil der Künstliche Intelligenz Forschung ausmacht. Die Künstliche Intelligenz als Feld ist allerdings noch viel weniger systematisiert und beinhaltet vom Prinzip alle Methoden und Versuche das menschliche Gehirn nachzuahmen. Insofern ist der Begriff sehr breit und schwer abgrenzbar.
M – Competitions
Auch umstritten sind allerdings noch die konkreten Erfolge des Machine Learnings im Vergleich zu den üblichen statsitschen Methoden. Die New York University und University of Nicosia veranstalten die sogenannten M – Competitions (ofizielle Webseite). Bei diesem Wettebewerb geht es darum, die beste Vorhersagemethode für einen Datensatz zu finden. Es konkurrieren regelmäßig Teams aus der ganzen Welt und versuchen mit ihren Modellen die besten Vorhersagen anhand der gegebenen Daten zu treffen. Bislang gewann aber eher ein Mix aus den üblichen Methoden der Statistik und des maschinellen Lernens. Die Modelle, die reines Machine Learning angewandt haben sind dort eher schlecht ausgefallen. Hier ein interessanter Fachartikel über die Ergebnisse aus dem Wettbewerb.
Obwohl der Optimismus groß ist, sollten wir vorerst nicht hoffen, dass Machine Learning die Anwendung der üblichen statistischen Methoden ersetzt. Dafür sind die Ergebnisse noch nicht zuverlässig genug.
Quellen:
Aurélien Géron: „Hands-On Machine Learning with scikit-learn and TensorFlow: Concepts, Tools and Techniques for Building Intelligent Systems“ (bei Amazon)






{kind=link}
Wenn man Leuten etwas einfach zu verstehen geben möchte, ist es oft hilfreich bzw. sehr hilfreich, es einfach in ihrer Sprache zu sagen.
Also beispielsweise nicht „content management system“ dem Handwerker-Kunden, oder Anwalt-Kunden oder der Nagelfee oder sonstigem Kunden an den Kopf zu werfen, sondern ihm bei der neuen Webseite zu erklären:
Sie haben ein Inhalts-Verwaltungsystem.
Dann geht es in den Kopf leicht verständlich rein und wird sofort verstanden.
Ähnlich bei „machine learning“. Warum nicht einfach „maschinelles Lernen“ sagen, dann weiß jeder gleich, um was es geht und versteht.
„Daten verstehen“, da würde ich das V noch kleinschreiben, weil kein Selbstwort (Substantiv), aber vermutlich hängt es mit der WP-Vorlage (dem „WP theme“) zusammen, daß das so ist?
Danke für Ihre Hinweise. Ich dachte Machine Learning passt besser zusammen mit Deep Learning. Vielleicht schreibe ich aber auch einen Beitrag, wo ich dann Machinelles Lernen schreibe bzw. beide Begriffe verwende. Daten Verstehen schreibe ich groß aus optischen Gründen.
Thema Sprache / Überschrift:
Das ist ungefähr so wie wenn man bei Daten einfach schreibt 1 + 3 = 7, weil 7 optisch besser aussieht oder besser klingt.
Ich würde, wenn es um Optik geht, dann „Daten verstehen“ einfach komplett großschreiben „DATEN VERSTEHEN“.
(wobei ich persönlich nicht weiß, was an „Daten verstehen“ häßlich aussehen soll; Sprache hat nunmal Groß- und Kleinschreibung und genauso wie es bei Datenverarbeitung und Zahlen (mathematische) Regeln gibt, gib es sie auch bei Sprache.
Sie haben mich überzeugt. Nach und nach werde ich die Webseite auf DATEN VERSTEHEN umstellen. Danke!