

Wie umfangreich müssen Datensätze sein um als Big Data zu gelten? Für manch einen ist bereits eine etwas größere Excel-Tabelle „Big Data“. Zum Glück gibt es bestimmte Eigenschaften, die uns erlauben Big Data ziemlich gut zu beschreiben.
Laut IBM wurden 90% der heute weltweit exisiterenden Daten allein in den letzten 2 Jahren erschaffen:
„This data comes from everywhere: sensors used to gather shopper information, posts to social media sites, digital pictures and videos, purchase transaction, and cell phone GPS signals to name a few. This data is big data.“ (IBM Webseite)
Big Data Definition
Am einfachsten lässt sich sagen: Big Data sind Daten, die nicht mehr nur von einem Rechner bearbeitet werden können. Sie sind so groß, dass man sie auf mehreren Servern stückweise speichern und bearbeiten muss.
Der deutsche Begriff Massendaten spiegelt die Eigentschaften der Big Data sehr gut. Es sind eben Massen an Daten, die zudem häufig diverse Formate haben.
Eine knappe Definition lässt sich auch auf Englisch durch drei Vs ausdrücken:
- Volume – beschriebt die Größe der Daten
- Variety – Vielfalt der Daten
- Velocity – Geschwindigkeit der Daten
Volume – die Größe der Daten
Wie bereits gesagt, Big Data lässt sich am einfachsten durch ihre schiere Menge und Komplexit beschreiben. Diese Eigenschaften lassen es nicht zu, Big Data nur auf einem Rechner zu speichern oder zu bearbeiten. Aus diesem Grund werden diese Daten in speziell dafür entwickelten Software-Ökosystemen gespeichert und bearbeitet, wie z.B. Hadoop.
Variety – Datenvielfalt
Massendaten sind sehr vielfältig und können zudem strukturiert, unstrukturiert oder semi-strukturiert vorkommen.
Diese Daten haben auch meistens unterschiedliche Quellen. Zum Beispiel könnte eine Bank Überweisungsdaten ihrer Kunden speichern, aber auch Aufnahmen von Telefongespräche ihrer Kundenbetreuung.
Vom Prinzip ist es sinvoll Daten in dem Format zu speichern, in dem sie aufgenommen worden sind. Das Hadoop Framework ermöglicht Firmen genau das: die Daten werden in dem Format gespeichert, in dem sie aufgenommen worden sind.
Es ist mit Hadoop nicht nötig, Kundengesprächsdaten in Textdateien zu konvertieren. Sie können direkt als Audiogespräche gespeichert werden. Allerdings ist dann auch die Anwendung von herkömmlichen Datenbankstrukturen nicht möglich.
Velocity – Datenschnelligkeit
Hier geht es um die Schnelligkeit, in der die Daten gespeichert werden.
Häufig ist es nötig, dass Daten in Echtzeit gespeichert werden. Für Firmen wie Zalando oder Netflix ist es somit möglich, ihren Kunden Produktempfehlungen in Echtzeit anzubieten.
Apache Hadoop Framework
Um diese spezielle Eigenschaften und Anforderungen von Big Data zu erfüllen, wurde das Hadoop Framework als open source entworfen. Es besteht grundsätzlich aus zwei Bestandteilen:
HDFS
Erstens: Es speichert Daten auf mehreren Servern (in Clustern) als sogenannte HDFS (Hadoop Distributed File System) und
Zweitens: bearbeitet es diese Daten unmittelbar auf den Servern, ohne sie auf einen Rechner herunterzuladen. Das Hadoop System bearbeitet die Daten also dort, wo sie gespeichert werden. Dies geschieht mittels eines Programms mit dem Namen MapReduce.
MapReduce
MapReduce bearbeitet die Daten parallel auf den Servern, und zwar in zwei Schritten: zunächst kommen kleinere Programme, sog. „Mapper“ zur Anwendung. Mapper sortieren die Daten nach Kategorien. Im zweiten Schritt bearbeiten sogenannte „Reducer“ die kategorisierten Daten und berechnen die Ergebnisse.
Hive
Die Bedienung von MapReduce erfordert Programmierkenntnisse. Um diese Anforderung etwas zu erleichtern, wurde ein weiterer Überbau auf dem Hadoop-Famework geschaffen – Hive. Hive erfordert keine Programmierkentnisse und setzt auf dem HDFS und MapReduce Framework auf. Die Befehle in Hive erinnern an die Befehle in SQL, einer Standardsprache für Datenbankanwendungen, und werden dann erst im zweiten Schritt in MapReduce übersetzt.
Der Nachteil dabei: es benötigt etwas mehr Zeit, denn der Code wird ja noch ins MapReduce übersetzt.
Das Problem mit Big Data
Die Menge an verfügbaren Daten steigt exponentiell. Parallel dazu sinken auch die Kosten diese Daten zu speichern und aufzubewahren. Dies verleitet viele Unternehmen dazu, Daten vorsorglich zu speichern und prüfen, wie sie in Zukunft verwertbar werden. Soweit es sich hier um personenbezogene Daten handelt, ergeben sich dann natürlich auch datenschutzrechtliche Fragen.
Komplexe Use Cases vs einfache Stichproben
Als konkretes Beispiel wird zum Beispiel einem Unternehmen möglicherweise empfohlen die Audiodateien von Kundengesprächen zu speichern, um in Zunkuft auch potentiell die Artikulation der Stimmen der Kundenberater und Kunden analysieren zu können. Stellt sich die Frage, ob das so umfassend tatsächlich notwendig ist?
Nein, denn sollte ein Unternehmen in Zukunft tatsächlich die Kundenberatungsqualität im Hinblick auf (zum Beispiel) Artikulation oder Simmklang analysieren wollen, ist es empfehlenswerter, dies anhand von Stichproben zu tun.
Man muss eben nicht jederzeit alle Daten vorhanden haben. Für solche Datenanalysen eignen sich gezielt durchgeführte Stichproben bestens. Für eine Stichprobenerhebung ist auch der Aufbau einer komplexen Datenstruktur innerhalb eines Unternehmens nicht nortwendig und deswegen ist eine derartigen stichprobenbaiserte Lösung kostengünstiger.
Gefahr der Scheinkorrelation (spurious correlation)
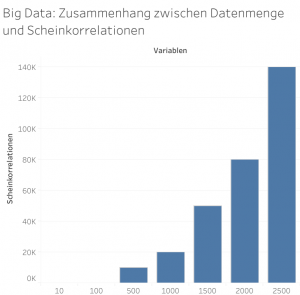
Big Data und Scheinkorrelation *Grafik inspiriert von N.Taleb (Wired)
Das bei weitem gefährlichste Phänomen im Zusammenhang mit Big Data ist die Gefahr der Scheinkorrelation. Je größer die Datenmenge, desto größer die Gefahr der Scheinkorrelation:
„We’re more fooled by noise than ever before, and it’s because of a nasty phenomenon called “big data.” With big data, researchers have brought cherry-picking to an industrial level.
Modernity provides too many variables, but too little data per variable. So the spurious relationships grow much, much faster than real information.
In other words: Big data may mean more information, but it also means more false information.“
Nassim Taleb für Wired („Beware the Big Errors of ‚Big Data'“).
Über die Gefahr der Scheinkorrelationen werde ich in diesem Blog später schreiben. Hier wollen wir diese Gefahr insbesondere im Hinblick auf Big Data im Grundsatz ansprechen.
Die Gefahr von falschen statistischen Zusammenhängen steigt mit der Anzahl der Variablen,und deswegen sind Massendaten hiervon besonders betroffen. Bei einer Simulation, die zufällig ca. 200 Variablen mit je 1.000 Observationen erstellt, würden allein durch Zufall verschiedene signifikante Zusammenhänge gezeigt, so Nassim Taleb.
Ein Data Scientist, der an einer Fragestellung mit Big Data arbeitet, kann relativ einfach alleine aufgrund der schieren Datenmenge Zusammenhänge herstellen, die es so nicht gibt, nämlich die besagten Scheinkorrelationen. Der Druck, igendwelche Zusammenhänge zu liefern ist groß – sowohl in Forschung als auch in der Industrie. Über Big Data lassen sich dann viele Zusammenhänge ermitteln, die als Handlungsempfehlungen herausgehen, obwohl sie reine Scheinkorrelationen sind. Big Data nicht richtig verstanden führt also leicht zu vemeintlich fundierten Entscheidungen, die letztlich fehlerhaft sind, weil die Entscheidungsgrundlage nicht richtig war.
Falsche Sicherheit mit Big Data
Big Data kann also ein Unternehmen in falscher Sicherheit wiegen. Man wiegt sich in Sicherheit durch datengetriebene Entscheidungsprozesse, allerdings auf Basis von welchen Daten werden diese Entscheidungen getroffen?
Dies lässt sich auch mittels einer Geschichte über Truthähne erklären, die an eine Idee aus Nassim Talebs Buch „Der Schwarze Schwan“ angelehnt ist.
Ausgangssituation:
Truthähne leben in einem Stall. Zwei mal pro Tag kommt ein Landwirt und gibt den Truthähnen etwas zum essen.
Die Truthähne sammeln Informationen zum gesamten Prozess der Fütterung, um die zukunftigen Fütterungszeiten vorauszusagen. Daraus entsteht über die Zeit Big Data mit folgenden Beispielvariablen: Wie ist der/die Landwirt/Landwirtin angezogen, genaue Uhrzeit der Fütterung, Anzahl der Körner usw.
Auf diese Weise haben dir Truthähne recht viele Daten gesammelt und können sich relativ sicher über die Zeit der nächsten Fütternung fühlen.
Thanksgiving
Am Tag der Thanksgiving kommt die Landwirtin und bringt alle Truthähne um.
Das Kritische daran ist: es passiert just an dem Tag an dem die Truthänhe die meisten Daten gesamelt haben und ihre Sichreheit somit am höchsten war. Dies lässt sich durch folgende Grafik zeigen:

Hier sieht man es ganz deutlich: egal wieviele Daten die Truthähne vor Thanksgiving gesammelt hätten – es wäre ihnen damit nicht geholfen, denn es waren die „falschen“ Daten. Oder anders gesagt, wenn wir nicht die Faktoren (die Variablen) kennen, die tatsächlich für eine bestimmte Fragestelleung entscheidungserheblich sind, werden wir mit hoher Wahrscheinlichkeit eine falsche Entscheidung treffen. Big Data ist sinnvoll – allerdings müssen wir, um Big Data richtig nutzen zu können, uns erst einmal vertieft mit der Frage auseinandersetzen, welche Datensätze tatsächlich entscheidungserheblich für die Frage sind, die wir mit Hilfe einer Datenanalyse beantworten wollen. Ohne dieses Verständnis ist Big Data nichts weiter als ein großer Nebel, der einen klaren Blick durch technikgläubige Sicherheit verstellt.
Einführung in Big Data: empfehlenswerte Onlinekurse
Es gibt mittlerelweile sehr viele Onlinekurse, die kostenfrei einen Überblick über das Thema Big Data verschaffen.
Bislang kann ich folgende Kurse empfehlen:
Udacity: Intro to Hadoop and MapReduce
Die Zusammenfassung von Hadoop Framwork in diesem Beitrag habe ich auf der Basis von diesem Kurs geschrieben. Der Kurs ist eine sehr gute Einführung in das Thema, die auch ohne jegliche Vorkenntnisse gut zu verstehen ist. Man muss nur mit den Beispielen für die Usecases aufpassen. Die Autoren arbeiten selbst in diesem Bereich und empfehlen dementsprechend viele Usecases für Big Data, u.a. die oben genannte Speicherung der Telefongespräche als Audiodateien.
Udacity: Intro to Data Science
In diesem Kurs gibt es eine Lektion „MapReduce“, die auch konkret auf die Big Data Thematik eingeht. Hier wird bereits ganz konkret auch die Anwendung präsentiert. Diesen Kurs empfehle ich für jemanden, der bereits etwas Programmiererfahrung mitbringt.
Falls ich noch weitere interessante Kurse entdecke, werden ich diesen Beitrag entsprechend „updaten“.







{kind=link}
Trackbacks/Pingbacks