

Im heutigen Beitrag möchte ich eine einfache Anleitung zur Datenvisualisierung in Python erstellen und zeigen, wie der Prozess in seinem gesamten Ablauf ausschauen kann. Um eine Visualisierung zu erstellen, werden wir das Beispiel aus dem vorherigen Artikel zu Straßenverkehrsunfällen in Deutschland benutzen.
Wie erstelle ich einfache Visualisierungen in Python?
Die Kunst der Datenvisualisierung ist eine Wissenschaft für sich. Die Softwareprodukte, die uns bei der Datenvisualisierungen unterstützen, können vom Prinzip in zwei Sorten geteilt werden.
Zum einem gibt es Software wie Excel oder Tableau. Hier sehen die Visualisierungen relativ schnell gut aus und können auch vergleichsweise einfach erstellt werden. Im Fall von Tableau geht es sogar bereits mit einem Drag-and-Drop Verfahren. Eine Anleitung zur Datenvisualisierung in Tableau habe ich hier geschrieben. Diese (relative) Einfachheit hat allerdings auch ihre Nachteile. Diese Softwareprodukte sind nicht kostenfrei und sie sind ziemlich unflexibel. Sie arbeiten mit gewissen Vorlagen, das heißt die Daten müssen auf das jeweilige System stark angepasst werden.
Wenn wir eine größere Flexibilität für unsere Datenvisualsierungen benötigen, kommen wir um Programmiersprachen wie Python nicht herum. In Python sind Visualisierungen zunächst nicht so einfach zu erstellen wie vielleicht mit Excel. Auch sind sie nicht so schön wie in Tableau. Die Eingangsschwelle liegt höher. Wenn sie allerdings erstmal überwunden ist, bietet Python deutlich mehr Alternativen und Spielraum. Last but not least, Python ist eine Open-Source-Anwendung.
Python Installation – Voraussetzungen
Um eine Visualisierung mit Python zu erstellen, müssen ein paar (offensichtliche) Bedingungen erfüllt sein. Zu diesen Schritten werde ich in Zukuft einen weiteren Beitrag verfassen. Heute spreche ich sie nur kurz in ein paar Punkten an.
Es muss softwaretechnisch Folgendes auf dem PC installiert sein:
- Python als Programmiersprache: zu finden auf der offiziellen Webseite. Hier noch eine Anleitung zur Installation, gefunden auf Youtube.
- Anaconda (Paket Manager für Python) sowie Jupyter Notebook (Notitzbuch für Datenanalyse). Beide Produkte sind Open Source und können auf den Anaconda und Jupyter Webseiten gefunden werden: anaconda.org und jupyter.org. Eine Anleitung zur Installation habe ich auf Youtube gefunden.
- Im dritten Schritt müssen die entsprechenden Pythonpakete via Anaconda installiert werden. Hierzu muss man im Anaconda Prompt einfach „conda install [paketname]“ schreiben. Hierzu habe ich auch ein Youtube Video gefunden. Die benötigten Pakete: Pandas und Matplotlib.
1. Daten herunterladen und anpassen
Für das Beispielprojekt nutze ich die Daten des Statistischen Bundesamts Destatis. Konkret geht es um die Tabelle 0007 – Verkehrstatistiken in der GENESIS Datenbank. Die Datenbank verfügt über ein sehr breites Angebot an Daten zu Verkehrstatistiken. Allerdings können die GENESIS-Tabellen auch Probleme bereiten. Zum einen ist es teiweise schwierig nachzuvollziehen, was die einzelnen Kolumnen bedeuten. Zum anderen kann man oft die einzelnen augewählten Datenreihen nicht herunterladen, sondern nur die Gesamtheit an Daten und hat am Ende eine größere Tabelle als eigentlich benötigt. Dies bedeutet mehr Arbeit in Excel und Python bei der Datenbereinigung.
Aus der GENESIS-Datenbank habe ich die Daten zu Verkehrsunfällen mit Kindern unter 15 Jahre alt als CSV-Datei heruntergeladen.
Obwohl ich versucht habe die Daten als reine Textdateien herunterzuladen, enthielt die CSV-Datei dennoch diverse Formatierungen der GENESIS Datenbank. Diese Formatierungen habe ich in Excel manuel gelöscht.
Zusätzlich ist es in GENESIS, wie bereits geschrieben, nicht immer möglich nur die gewünschten Daten als Tabelle herunterzuladen. Man erhält weitere Daten in der Tabelle dazu. So sah beispielsweise die Tabelle in ihrer Ursprungsform in meinem Fall aus:
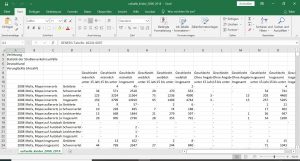
Die Tabelle enthält viel mehr Informationen, als ich für meine Zwecke brauche. Hier möchte ich einfach nur die getöteten Kinder unter 15 im Straßenverkehr von 2008 bis 2018 erfassen. Aus diesem Grund musste ich die Tabelle manuell im Excel verändern. Hier das Endergebnis:
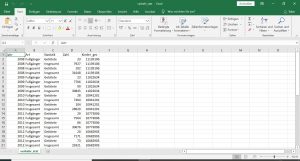
Bei größeren Datenmengen empfiehlt sich eine direkte Bereinigung in Python. Das Problem dabei sind immer die zusätzlichen Formatierungen. Ihre Enfernung geht oft schneller in Excel.
2. Die Tabelle in Python einspeisen
Im zweiten Schritt kann die Tabelle mittels Pandas mit folgendem Code als dataframe geöffnet werden.
# downloading data df = pd.read_csv('verkehr_stat.csv',sep=';', encoding='latin-1')
Der Befehl zum Abrufen der CSV-Datei ist immer gleich. Allerdings können sich die Zusatzelemente wie „encoding“ verändern. Hier muss man ein wenig testen, was funktioniert, damit das Dokument gut lesbar wird.
Die Tabelle in Python schaut jetzt folgendermaßen aus:
| Jahr | Art | Statistik | Zahl | Kinder_ges | |
|---|---|---|---|---|---|
| 0 | 2008 | Fußgänger | Getötete | 23 | 11139106 |
| 1 | 2008 | Fußgänger | Insgesamt | 7927 | 11139106 |
| 2 | 2008 | Insgesamt | Getötete | 102 | 11139106 |
| 3 | 2008 | Insgesamt | Insgesamt | 31648 | 11139106 |
| 4 | 2009 | Fußgänger | Getötete | 23 | 11022634 |
| 5 | 2009 | Fußgänger | Insgesamt | 7706 | 11022634 |
| 6 | 2009 | Insgesamt | Getötete | 90 | 11022634 |
| 7 | 2009 | Insgesamt | Insgesamt | 30845 | 11022634 |
| 8 | 2010 | Fußgänger | Getötete | 28 | 10941201 |
| 9 | 2010 | Fußgänger | Insgesamt | 7304 | 10941201 |
3. Visualisierung
Im dritten Schritt werden die Daten in der Tabelle so aufgearbeitet, dass wir nur die Kennzahlen darin haben, die wir tatsächlich visualisieren möchten. Hier zeigt sich die Flexibilität Pythons, denn die Möglichkeiten sind vielfältig.
Das Ziel ist es, die Zahl der getöteten Kinder unter 15 in Deutschland zwischen den Jahren 2008 und 2018 darzustellen.
Hierzu erstellen wir einen neuen Datensatz aus dem vorherigen Dataframe (df).
gesamt_stat = df[df['Art'] == 'Insgesamt'] # Ausfiltern von Fußgängerstatistiken gesamt_get = gesamt_stat[gesamt_stat['Statistik'] == 'Getötete'] # Ausfiltern von gesamten Unfällen
Der neue Datensatz gesamt_get enthält dann nur die Angaben zu der Gesamtzahl der im Straßenverkehr getöteten Kinder unter 15 in Deutschland zwischen den Jahren 2008 und 2018.
gesamt_get
| Jahr | Art | Statistik | Zahl | Kinder_ges | |
|---|---|---|---|---|---|
| 2 | 2008 | Insgesamt | Getötete | 102 | 11139106 |
| 6 | 2009 | Insgesamt | Getötete | 90 | 11022634 |
| 10 | 2010 | Insgesamt | Getötete | 104 | 10941201 |
| 14 | 2011 | Insgesamt | Getötete | 86 | 10773006 |
| 18 | 2012 | Insgesamt | Getötete | 73 | 10682903 |
| 22 | 2013 | Insgesamt | Getötete | 58 | 10642432 |
| 26 | 2014 | Insgesamt | Getötete | 72 | 10686723 |
| 30 | 2015 | Insgesamt | Getötete | 84 | 10881126 |
| 34 | 2016 | Insgesamt | Getötete | 66 | 11048568 |
| 38 | 2017 | Insgesamt | Getötete | 61 | 11171759 |
| 42 | 2018 | Insgesamt | Getötete | 79 | 11290815 |
Im Anschluß können wir die Daten mittels Matplotlib visualisieren. Hierzu reicht der folgende Code:
plt.plot('Jahr', 'Zahl', data=gesamt_get) plt.xlabel('Jahr') plt.ylabel('Kinder unter 15') plt.title('Getötete Kinder unter 15 im Straßenverkehr')
plt.plot('Jahr', 'Zahl', data=gesamt_get) plt.plot - sagt dem Matplotlib, dass wir ein Plot erstellen möchten
plt.xlabel('Jahr') - Bestimmen, welche Daten die X-Achse abbilden plt.ylabel('Kinder unter 15') - Bestimmen, welche Daten die Y-Achse abbilden plt.title('Getötete Kinder unter 15 im Straßenverkehr') - Titelnennung
Ergebnis
Mit diesem Code erhält man folgende Visualisierung:
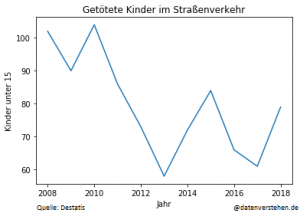
Die Viusalisierungen mit Matplotlib sehen optisch nicht so schön aus wie die Grafiken in beispielsweise Tableau. Allerdings haben sich auch Python-Pakete weiterentwickelt und es gibt neuere Anwendungen, wie beispielsweise Seaborn, die eine schönere Farbenpalette anbieten.
Das Unschlagbare an Python bleibt die Flexibilität und Bequemlichkeit alles zusammen in einem Jupyter Notebook zu gestalten.
Der schwierigste Teil, insbesondere im Vergleich zu Excel und Tableau, ist die Installation der Software und die ersten Schritte. Sobald man jedoch die erste Anwendung bedienen kann, bietet Python viel mehr Möglichkeiten als andere Softwareprodukte.
Der Code für das gesamte Projekt befindet sich auf meiner Github-Seite (Link).
Bei Fragen zu den Datenvisualisierungen könnnen Sie mich gerne unter info@datenverstehen.de kontaktieren oder eine Nachricht in den Kommentaren schreiben.
Bild von Photo Mix auf Pixabay







{kind=link}
Trackbacks/Pingbacks