
Dieser Beitrag ist der erste aus der Reihe: Datengewinnung und Analyse aus Social Media mit Python. In der ersten Folge werden wir das Social Media Mining am Beispiel von Twitter kennenlernen. Heute geht es um den Zugang zum Twitter API und empfehlenswerte Pythonbibliotheken. Wir werden auch die ersten Trends auf Twitter recherchieren und darstellen.
Bevor wir Daten aus den sozialen Medien gewinnen und analysieren, ist es wichtig sich mit der jeweiligen Plattform auseinanderzusetzen. Ohne dieses Wissen ist es schwer die eingehenden Daten richtig zu interpretieren.
Was ist Twitter?
Twitter ist eine populäre Mikroblogging Plattform. Laut Hubspot können in Deutschland via Twitter über 5 Millionen Menschen erreicht werden. Zwar gehört Twitter nicht zu den am meisten genutzen Social Media Plattformen, trotzdem ist Twitter wegen seiner Aktualität relevant. Viele Politiker, Journalisten und auch Firmen nutzen Twitter als Kommunikationsplattform.
Die grundlegende Kommunikationsform auf Twitter sind die sogenannten Tweets. Ein Tweet darf 280 Zeichen beinhalten. In einem Tweet können die User Hashtags (# Zeichen) nutzen sowie andere User mit (@ Zeichen) markieren.
User können auch auf einen Tweet antworten. In diesem Fall kommt das @ Zeichen direkt am Anfang.
Eine weitere wichtige Funktion ist der Retweet. Eine Userin retweetet in so einem Fall einen Tweet eines anderen Users. So ein Tweet beinhaltet den Tweet der Ursprungsperson und (optional) einen Kommentar der retweetenden Person.
Ähnlich wie bei Instagram ist die zentrale Funktion bei Twitter das Follow. User können anderen Accounts folgen. Auf diese Art und Weise bauen die User eigene Reichweite aus. Eine Gegenseitigkeit in der Followerschaft (wie die Freundschaften auf Facebook) ist nicht notwendig. Somit können manche User eine große Followerschaft und Reichweite aufbauen.
Das Nutzen von Hashtags und eine große Followerbasis haben das Potential auf Twitter starke Netzwerkeffekte und somit Viralität zu erzeugen.
Eine ausführliche Zusammenfassung der Twitterfunktionalitäten bietet auch dieser Artikel auf heise online.
Zugang zum Twitter API (Python Bibliotheken)
Die Twitterdaten erreichen wir über das sogenannte Twitter API (Application Programming Interface). Vereinfacht gesagt, erlaubt die API unserem Rechner eine Verbindung zu Twitter Software herzustellen. Auf diese Art und Weise kann unser Skript über die API mit Twitter kommunizieren und Daten abrufen.
Um Zugang zum Twitter API zu erhalten ist eine Anmeldung als normaler Nutzer bei Twitter notwendig. Danach „bewirbt“ man sich um einen Developer Account: hier auf Twitter. Twitter ist sehr großzügig und im Regelfall klappt es mit dem Zugang recht schnell.
Ein Schritt in der Bewerbung (und auch nach der Bewerbung) ist das Erstellen einer App auf Twitter. Hierzu schreiben wir eine Beschreibung, was genau die App machen soll und welche Twitter-Daten hierzu benötigt werden.
Bei der Anmeldung einer App auf Twitter erhaltenwir die sogenannten Identikationskeywords (Passwörter): consumer key, consumer secret, access token, access token secret. Diese sind notwendig, damit wir uns beim Abruf der Daten bei Twitter identifizieren können. Dabei hat jede App eine eigene Identifikation. Dies ist insofern sinvoll, als dass wir den Zugang für die App an Dritte vergeben können, ohne Zugangsdaten zu unserem Developer Account preiszugeben.
So sieht mein Twitterdeck nach einer erfolgreichen Anmeldung einer App aus:
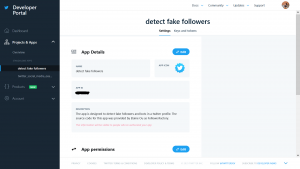
Rechts unter dem App Titel sieht man die „Keys and Tokens“, die die vier Zugangspasswörter beinhalten.
Python Bibliotheken (Zugang zum Twitter API)
In Python gibt es einige Bibliotheken, die uns den Abruf der Twitter Daten erlauben.
Twitter / Python-Twitter
Eine der populärsten ist die Bibliothek „Twitter“. Sie wird auch im Buch „Mining the Social Web“ von Mathew A. Russel & Mikhail Klassen für Anfänger empfohlen.
Leider kann ich dieses Bibliothek nicht empfehlen. Die Installation klappt nicht unbedingt. Auch funktionieren die Anwendungen und Skripte nicht immer.
Tweepy
Tweepy gehört auch zu den populärsten Python-Biblitheken für die Arbeit mit den Twitter-Daten. Im Gegensatz zu „Twitter“ habe ich mit Tweepy bislang nur gute Erfahrungen gemacht.
Installation
Je nachdem mit welchen Tools man arbeitet, kann man Tweepy unterschiedlich installieren.
Zum einen auf dem Computer via Command Line: pip install tweepy
In der Jupyter / Anaconda Umgebung gibt man im Anaconda Prompt ein:
conda install -c conda-forge tweepy
Sollte dies nicht klappen, gibt es auch weitere Befehle auf der offiziellen Anaconda Webseite.
Abrufen der Twittertrends mit Tweepy
In diesem Kapitel arbeiten wir weiter im Jupyter Notebook (man kann es aber genauso in jeder anderen Umgebung durchführen). Das Skript für diesen Teil kann auch auf Github (hier) abgerufen werden.
Zunächst (1) importieren wir Tweepy und (2) geben unsere Eingangsdaten (keys and tokens) für Twitter ein.
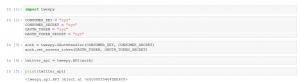
In (3) und (4) nutzen wir die sogenannte OAuth, um sich bei Twitter zu identifizieren. Im letzten Schritt überprüfen wir, ob unser Zugang zum Twitter API tatsächlich funktioniert.
Jetzt geht es darum zu sehen, was gerade auf dem deutschen Twitter trendet. Hierzu brauchen wir die WOEID-Kennzahl. WOEID bedeutet „Where On Earth IDentifier“ und markiert mit einer Zahl verschiedene geografische Orte auf unserem Planeten.
Wir können nach der WOEID Markierung für Deutschland auf der Webseite findmecity.com suchen.
Die WOEID für Deutschland ist: 23424829
Im nächsten Schritt geben wir die WOEID als Variable ein. Mit Hilfe von Twitter API-Objekt können wir im Anschluss die Trends für die angegebene WOEID ziehen:
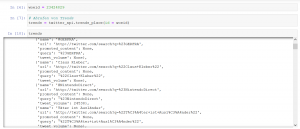
Twitter stellt uns die Ergebnisse (hier eben die abgefragten Trends) in einer Art von JSON – Format bereit. Zu JSON (JavaScript Object Notation) als Datenformat wird es einen weiteren Blogbeitrag geben. Um mit JSON in Python zu arbeiten, muss man einige Transformationen vornehmen (hier die Basics, wie man mit JSON in Python arbeitet).
Um die Trends einfach und schnell lesbar zu machen, kann man sie mit Hilfe des folgenden Skripts bearbeiten.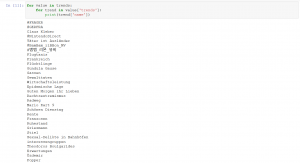
Um Daten aus komplexeren Abfragen zu bearbeiten, ist das Arbeiten mit der json-Bibliothek in Python notwendig. Darüber wird es einen weiteren Blogbeitrag geben.
Quellen:
Mit Hilfe folgender Quellen und Skripte habe ich diesen Beitrag verfasst:
„Mining the Social Web“ Matthew A. Russel & Mikhail Klassen (Skripte aus dem Buch sind auch auf Github verfügbar). Die Autoren nutzen aber „Twitter“ Bibliothek und nicht Tweepy.
Geeks For Geeks: API Trends mit Tweepy.






{kind=link}
Hi Alex, endlich habe ich Zeit gefunden mir das Account anzuschauen und tatsächlich gibt es auf dem Account einige Unregelmäßigkeiten.…
Hallo, ich werde mir das Profil angucken und poste hier, was ich gefunden habe. Ich brauche aber noch ca. Eine…
Hi Aleksandra, ich glaube, mit deiner Analyse könntest du vielen Menschen helfen, die betrogen werden. Insbesondere in der Krypta-Welt. Dort…
Größerer und allumfassender Algorithmus: Die Schwerkraft ist keine Kraft, die von A nach B reicht, sondern ein grundlegendes und elementares…
Hallo, ja. es geht um dieses Projekt (optiizedSD=Projekt von Basu Jindal)