

KI Themen gewinnen in Deutschland an Popularität. Viele Unternehmen (zunehmend auch mittelständische) wollen ihre KI-Strategie verbessern und planen vermehrt Data Scientists und/oder Data Engineers einzustellen um das Unternehmen im KI-Wettbewerb gut zu positionieren. Es ist offenbar vor allem „in“, etwas mit Deep Learning zu machen.
Ich habe den Eindrück gewonnen, es werden insbesondere Datenexperten für Senior Rollen gesucht. Zum einen wollen die Unternehmen vermutlich zunächst klein anfangen und die Möglichkeiten von KI-Anwendungen erstmal testen, zum anderen lässt sich so schnell ein Team aufbauen, sollten die Themen im Unternehmen tatsächlich an Bedeutung gewinnen.
Dieser Drang in die KI Richtung wird durch Angst, den sogennanten FOMO (fear of missing out) getrieben. Man will den nächsten Trend nicht verpassen und testet die neue Strategie mit zunächst vielleicht mal einer Person um die Kosten so gering wie möglich zu halten.
Nehmen wir mal an, das Unternehmen hat diese Person (Data Scientist) gefunden. Die Hoffnungen auf beiden Seiten sind groß. Der angestellte Data Engineer hofft gute Strukturen vorzufinden, um diese Modelle zu implementieren. Das Unternehmen erwartet Ergebnisse, am besten, wenn da etwas mit Deep Learning stattfindet.
In sehr vielen Fällen werden jedoch die Hoffnungen enttäuscht. Zunächst einmal wird der Data Scientist enttäuscht sein, denn er erwartete zeitnah mit den Anwendunge zu beginnen. Was er jedoch stattdessen vorfindet, ist eine Vielfalt an Daten, die unterschiedlche Formate haben und auch auf verschiedenen Datenbanken quer im Unternehmen verteilt sind oder gar erst gewonnen werden müssen. Dies bedeutet letztendlich, dass der neue Angestellte großen Zeitaufwand betreiben muss, um überhaupt die Daten zu gewinnen und in die richtige Form zu bringen. Danach müssen die Daten auch noch bereinigt werden. Dies wird eine lange Zeit dauern.
Was denken sich dann die Entscheider im Unternehmen? Sie sind selbstverständlich enttäuscht, denn sie haben erwartet, die Ergebnisse zeitnah zu sehen und dies scheint nicht möglich zu sein. Die Sekpsis des Unternehmnens bezüglich KI wird womöglich wachsen.
Hier setzt die Data Consultant Monica Rogati mit ihrem Beitrag auf Medium: „The AI Hierarchy of Needs“ an. Sie schägt eine konzeptionelle Lösung für dieses Problem vor, die die Unternehmen bei der Implementierung ihrer KI Strategie bedenken sollten. Es geht um Infrastruktur-Bedingungen, die erfüllt werden müssen, bevor ein Unternehmen komplexe Machine Learning Modelle überhaupt anwenden kann. Rogati stellt die KI-Strategie im Unternehmen als eine Pyramide dar.
KI – Bedürfnispyramide
Die KI-Strategie für ein Untermehmen muss entlang der KI – Bedürfnispyramide strukturiert sein. Um komplexe Modelle zu implementieren, muss als erstes die grundlegende Dateninfrastruktur vorhanden sein.
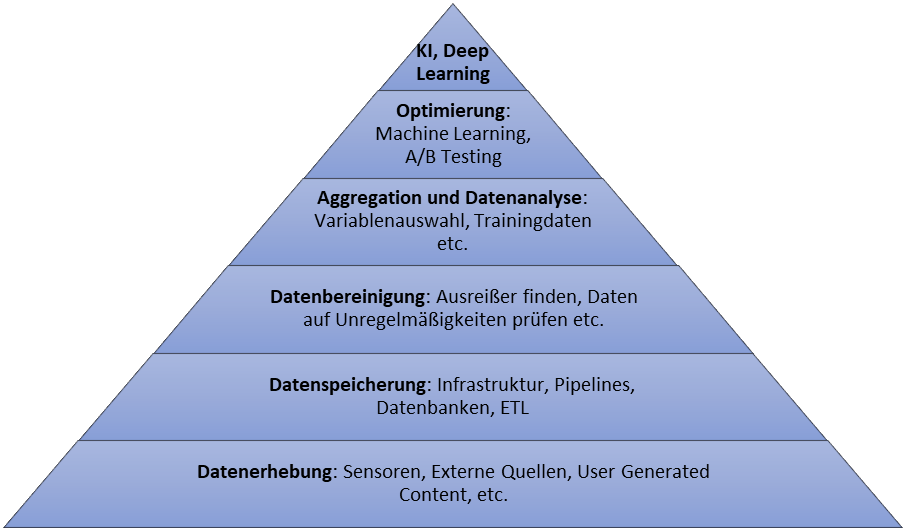
Quelle: Monica Rogati: „The AI Hierarchy of Needs„
1. Dateninfrastruktur
Die KI-Strategie im Unternehmen steht und fällt demnach mit der richtigen Dateninfrastruktur. Wir können nicht erwarten, dass ein Data Engineer ohne eine vorhandene Dateninfrastruktur sofort Modelle aufsetzt und Ergebnisse präsentiert. Die entsprechenden Daten müssen vorhanden sein oder es muss klar sein, wie die Daten gewonnen werden können.
Eine weitere Voraussetzung ist die entsprechende Speicherung der Daten. Die Daten sollten richtig formatiert werden und leicht zugänglich sein. Die ETL Pipeline (Extract, Transform, Load) muss funktionieren.
In größeren Unternehmen können diese Funktionen geteilt werden. Ein Data Engineer würde in solchen Fällen dafür zuständig sein, die Dateninfrastruktur am Laufen zu halten während Data Scientist die KI-Modelle aufsetzen würde. Die Realität ist jedoch, dass viele Unternehmen sich zwei solche Spezialisten nicht leisten können und der Data Scientist übernimmt beide Funktionen. Umso wichtiger ist dann aber zu verstehen, dass diese Infrastruktur erst geschaffen werden muss, um überhaupt KI-Projekte zu realisieren – und das kann dauern.
Erst wenn diese Anforderungen erfüllt sind, können weitere Schritte erfolgen. Hier greift der bekannte Datenanalyse Prozess CRISP-DM ein, den ich in einem anderen Beitrag bereits dargestellt habe. Im ersten Schritt sind dann einfache Datenalysen sowie statistische Auswertungen möglich.
2. Training Data und Machine Learning
Erst wenn die vorherigen Schritte erfüllt worden sind, ist die Anwendung der Machine Learning Algorithmen denkbar. Hier ist es wichtig, die entsprechenden Daten zu sammeln um ein Test- und Trainingdataset zu erstellen. Die Daten sollen auch entsprechend beschriftet werden.
Wenn die Daten das Kosumverhalten der User betreffen, kann auch die Infrastruktur für die A/B Tests erstellt werden.
Die KI – Bedürfnispyramide zeigt, wie wichtig die richtigen Prozesse im Unternehmen sind, wenn es um die Dateninfrastruktur geht. Der erste Schritt in Richtung der Anwendung des Machine Learnings ist zunächst eine gut funktionierendes ETL Pipeline.
Unternehmensstrategie
Der Ansatz von Monica Rogati steht teilweise im Gegensatz zu dem Ansatz von Andrew Ng (beschrieben von mir hier). Ng empfiehlt mit einem kleinerem KI-Projekt zu starten um schnell Erfolge zu erzielen.
Ng´s Ansatz kann funktionieren, allerdings wird vermutlich so ein kleines Projekt letzen Endes wenig Aussagekraft über den potenziellen Nutzen für die gesamte Firma haben.
Rogatis Ansatz schlägt die Anpassung bzw. die Schaffung der Dateninfrasturktur als erster Schritt vor. Dieser Schritt scheint in jedem Fall sinvoll zu sein, auch wenn kein Experimentieren mit Machine Learning im Unternehmen ansteht. Mit dem Umschwenken auf datenbasierte Entscheidungen und Funktionen sollte auf jeden Fall auch eine gute Dateninfrastruktu aufgebaut weden. Dann steht dem Ausprobieren der KI-Algorythmen auch im größeren Umfang nichts im Wege.
Bild von Free-Photos auf Pixabay







{kind=link}
Hi Alex, endlich habe ich Zeit gefunden mir das Account anzuschauen und tatsächlich gibt es auf dem Account einige Unregelmäßigkeiten.…
Hallo, ich werde mir das Profil angucken und poste hier, was ich gefunden habe. Ich brauche aber noch ca. Eine…
Hi Aleksandra, ich glaube, mit deiner Analyse könntest du vielen Menschen helfen, die betrogen werden. Insbesondere in der Krypta-Welt. Dort…
Größerer und allumfassender Algorithmus: Die Schwerkraft ist keine Kraft, die von A nach B reicht, sondern ein grundlegendes und elementares…
Hallo, ja. es geht um dieses Projekt (optiizedSD=Projekt von Basu Jindal)