
Im heutigen Beitrag werden wir lernen, wie man aus Twitterdaten die am häufigsten benutzen Wörter extrahieren kann. Die häufigsten Wörter können sich auf einen Hashtag, eine Person oder auf ein spezifisches Wort beziehen. Mit dieser Methode können wir recht schnell Trends im Hinblick auf ein Wort oder eine Wortzusammensetzung auf Twitter erkennen.
Diese Art der Textanalyse ist ein rudimentärer Bestandteil des Natural Language Processing (NLP) (Deutsch: Computerlinguistik). Zu diesem Thema wird es hier bald weitere Beiträge geben.
Wie das Natural Language Processing in der Praxis funktioniert, habe ich bereits auf data-science-blog.com beschrieben. Eine ausführliche Definition wird noch folgen.
Das gesamte Skript für die folgende Analyse ist auf meinem Github Account (Link) verfügbar.
Ziel der Analyse: die häufigsten Wörter im Zusammenhang mit #Covid19
In diesem Breitag werden wir die Analyse der häufigsten Wörter im Zusammenhang mit dem Hashtag #Covid19 vornehmen: welche Wörter benutzen die User am häufigsten, wenn sie den Hashtag #Covid19 erwähnen?
Die häufigsten Wörter werden wir sowohl als Grafik als auch eine sogenannte Wortwolke präsentieren.
Was ist der Nutzen?
Solche Analysen sind insbesondere im Bereich Social Media Marketing interessant. Auf diese Art und Weise können Firmen beispielsweise messen, in welchem Kontext ihre Marke erwähnt wird. Auch kann ahand der Häufigkeiten der Wörter erkannt werden, mit welchem Sentiment und mit welchen Gefühlen die Nutzer einen bestimmten Hashtag oder eine Marke verbinden.
Ein weiteres Use Case ist die Entdeckung der Trends in Gesprächen. Beispielsweise könnte so eine Anwendug im Fall einer Naturkatastrophe helfen besonders betroffene Gebiete zu identifizeren.
Dieser Bereich des NLP wird auch oft als Social Media Listening oder auch Social Listening bezeichnet.
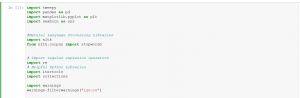
1. Importieren der entsprechenden Python Bibliotheken
Bibliotheken:
2. Twitter Login und das Abrufen von relevanten Daten
In diesem Schritt führen wir ähnliche Schritte wie im letzten Beitrag aus:
(1) Twitter API Login;
(2) Überprüfen, ob der Zugang zum Twitter API funktioniert.

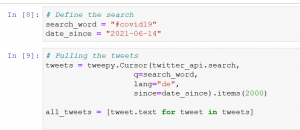
Twitter Query
Als letzten Schritt legen wir fest, welche Daten wir aus Twitter ziehen möchten. Für unsere Analyse ziehen wir die Tweets, die den Hashtag #Covid19 erwähnt haben.
Es gibt verschiedenen Modalitäten, wie wir die entsprechenden Inhalte aus Twitter extrahieren können. Zur Info empfehle ich hier die zwei Twitter-API Links:
und
Twitter Search Operators (erklärt, wie man verschiede Inhalte extrahieren kann).
Wichtig ist auch die Sprache als Deutsch zu definieren.
Um die Tweet-Inhalte mit Bezug zu einem Hashtag zu finden reicht folgende Suchanfrage:
Twitter Rate Limits (Standard API)
Der Standardzugang zum Twitter API begrenzt den Datenabruf in vielfacher Hinsicht. Man darf eine Anfrage nur alle 15 Minuten stellen. Auch werden mit einem Request ca 1500 bis 2000 Tweets heruntergeladen. Der Zeitrahmen der abgerufenen Tweets ist begrenzt auf 7 bis 10 Tage. Die Datenbeschränkungen sind auf der offiziellen Twitterseite aufgeführt.
Diese Beschränkungen kann man auf folgende Weise lösen.
- Zugang zu Premiumversion der Twitter API;
Twitter bietet uns auch einen Premiumzugang zu den Daten. Auf der offiziellen Twitter Developer Webseite gibt es genauere Infos zu diesem Thema.
- Die Daten aus den vorherigen Abfragen speichern und zusammenführen;
Man kann die abgerufene Teeets als json Dokument und Python Liste speichern und die Listen aus verschiedenen Abrufzeiten zusammenführen. Hier sind verschiedene Lösungen möglich.
Eine davon sieht wie folgt aus:
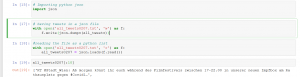
Hierzu (1) importieren wir die Python json-Bibliothek, die uns das Arbeiten mit Dateien im JSON Format erlaubt. Danach (2) speichern wir die abgerufenen Tweets als Liste und als json-Datei auf unserem Computer. Im nächsten Schritt (3) können wir die Tweet-Liste wieder abrufen bzw. hochladen.
Mehrere Listen können auf diese Weise erstellt und später zusammengeführt werden.
3. Bereinigung der Tweets und Vorbereitung der Textanalyse
Im nächsten Schritt bereinigen wir die Tweets und bereiten sie somit für die eigentliche Textanalyse auf. Die rohen Tweetdaten beinhalten viele Bestandteile, die eine quantitative Textanalyse erschweren, wie z.B. Smileys oder Webseitenlinks.
Je nachdem, was wir mit dem Text vorhaben, müssen wir entsprechende Inhalte löschen bwz. gar nicht erst herunterladen. Die Frage ist beispielsweise auch, wie man mit den Retweets umgehen möchte. Für manche Fragestellungen sind sie relevant, für andere nicht.
In unserem Fall sind die Retweets genauso relevant wie die eigentlichen Tweets, denn sie multiplizieren die Stimmung der User. Eine Userin, welche einen Tweet retweetet will ja die Wörter, die im Tweet enthalten sind weitergeben.
Entfernen der Webseitenlinks
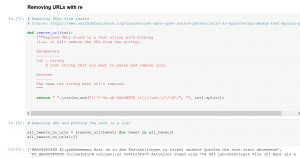
Skript Quelle: earthdatascience.org. Zusätzlich wurden in die Funktion von mir die Umlaute eingebaut. (Bearbeitung 08.09.2021: die Ergebnisse unten beinhalten keine Umlaute. Der Skript ist inzwischen verbessert und die Code Anleitung hier als auch auf GitHub beinhaltet auch die Umlaute).
Alle Wörter klein schreiben und Sätze trennen
Nach der oben durchgeführten Bereinigung sind die Tweets als reine Textdateien verfügbar. Im nächsten Schritt geht es darum, die Texte in reine Wörter umzuwandeln. Hierzu werden wir (1) mit der Python-Funktion lower() alle Wörter klein schreiben und (2) Mit dem split() Befehl Sätze in Wörter trennen.
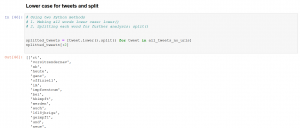
Die Tweets werden als Listen gespeichert. Jeder Tweet ist ein Listenobjekt. Mit der Funktion split() zerteilen wir jedes einzelne Listenobjekt(Tweet) in einzelne Wörter, siehe das obere Bild.
Stopwörter entfernen
Als Nächstes entfernen wir die sogenannten Stopwörter aus unserer Wörterlisten. Stopwörter sind Wörter, die in den Sätzen sehr häufig vorkommen und keine Relevanz für die Analyse bzw. Textinhalt haben. Zum Beispiel sind es Wörter wie aber, einer, manche, nur usw.
Hierzu nutzen wir Bestandteile der Python-NLTK Bibliothek „stop words“
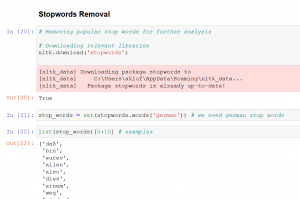
Wichtig ist dabei zu beachten, dass wir die deutschen Wörter herunterladen.
Im nächsten Schritt entfernen wir die entsprechenden Wörter aus unseren Listen:
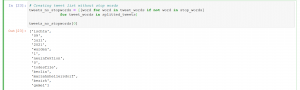
4. Textanalyse: die häufigsten Wörter auf Twitter
Unsere neue Liste heißt „tweets_no_stopwords“. Wir sehen aber, dass sie immer noch einge Stopwörter, die die NLTK Bibliothek nicht erkannt hat, beinhaltet. Trotzdem können wir jetzt den ersten Versuch unternehmen die 20 häufigsten Wörter in Verbindung mit dem Hashtag Covid19 zu erstellen. Dies kann man mittels folgendem Skript ermitteln:
Einge Stopwörter haben es hier auf die Liste geschafft. Diese können wir wie folgt entfernen:
(1) manuell erstellen wir eine Liste mit den vorkommenden Stopwörtern sowie dem Wort Covid19;
(2) wir entfernen diese Wörter aus unserer Liste (3) und lassen den Skript nochmal „laufen“.
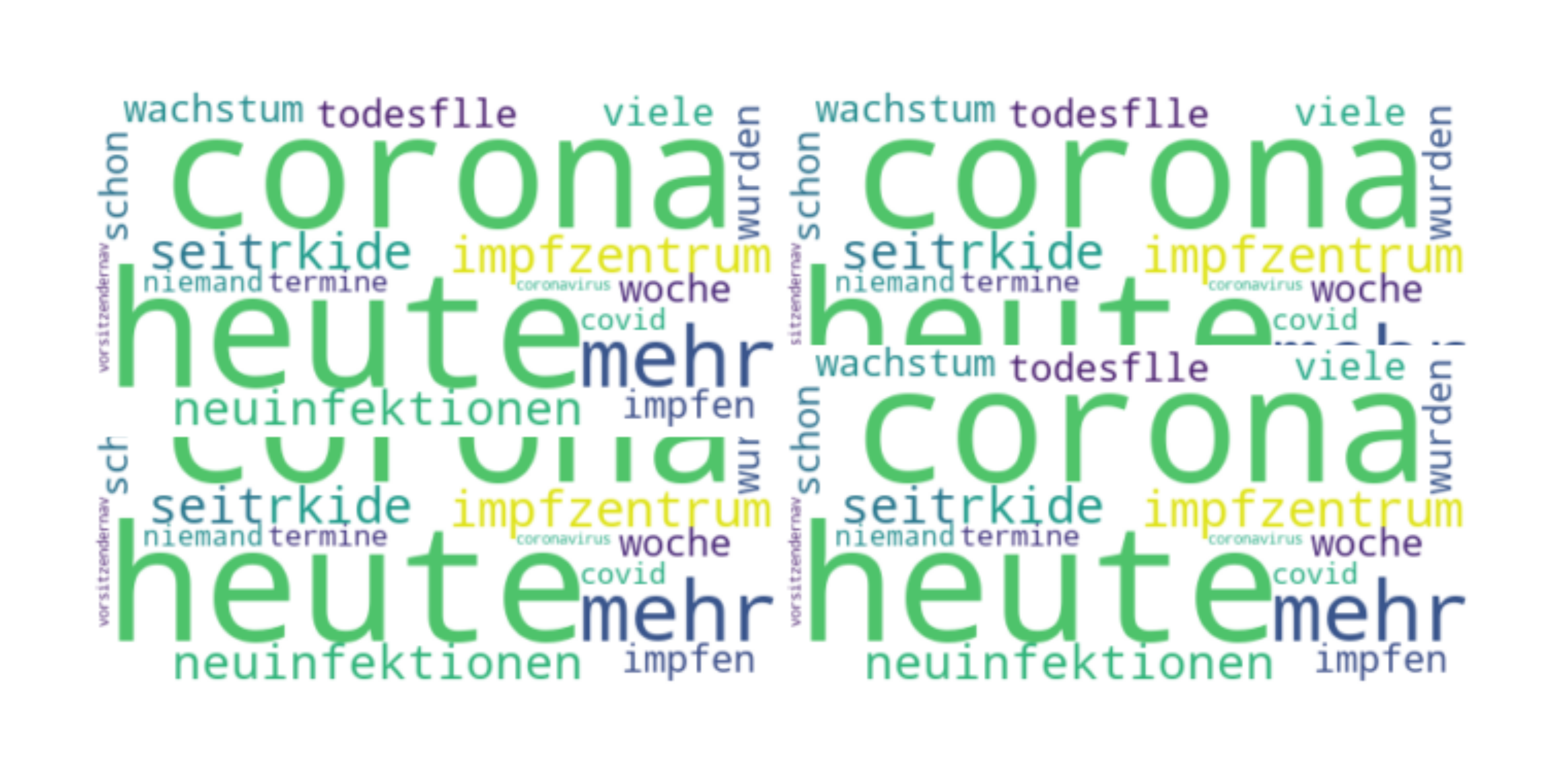
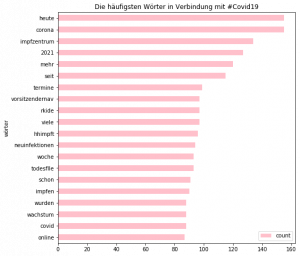
5. Visualisierung der häufigsten Wörter mit #Covid19
Zunächst wandeln wir undere Wörterliste in ein Pandas DataFrame um.

Visualisierung mit Pandas

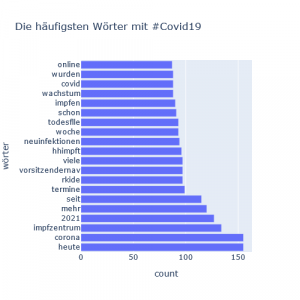
Visualisierung mit Plotly

Wortwolke mit den häufigsten Wörtern
Aus den häfigsten Wörter lässt sich auch eine Wortwolke erstellen. 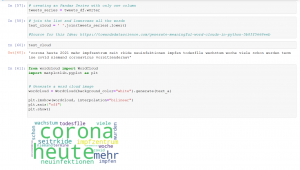
Die Erstellung der Wortwolken (Word Clouds) ist eine Wissenschaft an sich. Es gibt viele verschieden Möglichkeiten sie zu erstellen und schöner zu machen. Hierzu empfehle ich folgenden Beitrag auf Towards Data Science: „Generate Meaningful Word Clouds in Python„.
Anmerkung: Ich habe den Beitrag über mehrere Tage erstellt und die Daten aus Twitter jeweils neu entnommen. Aus diesem Grund kann die Häufigkeit der Wörter in den präsentierten Ergebnissen variieren.
Update 08.092021: Wie bereits vorne erwähnt beinhaltet das neue Skript auch die Umlaute. Die Ergebnisse selbst habe ich aber hier nicht mehr verändert. Die Code-Anleitung beinhaltet aber auch die Umlaute.







{kind=link}
Hi Alex, endlich habe ich Zeit gefunden mir das Account anzuschauen und tatsächlich gibt es auf dem Account einige Unregelmäßigkeiten.…
Hallo, ich werde mir das Profil angucken und poste hier, was ich gefunden habe. Ich brauche aber noch ca. Eine…
Hi Aleksandra, ich glaube, mit deiner Analyse könntest du vielen Menschen helfen, die betrogen werden. Insbesondere in der Krypta-Welt. Dort…
Größerer und allumfassender Algorithmus: Die Schwerkraft ist keine Kraft, die von A nach B reicht, sondern ein grundlegendes und elementares…
Hallo, ja. es geht um dieses Projekt (optiizedSD=Projekt von Basu Jindal)